tl;dr AKA Abstract
pestrPRA is a package that generates templates for Pest Risk Analysis (PRA) that can be easily filled with text, tables, pictures etc. Currently it supports 2 kinds of templates in English and 1 in Polish. All the templates are based on European and Mediterranean Plant Protection Organization EPPO Standards on Pest Risk Assessment (RESOURCES/eppo_standards/pm5_pra).
All the templates as an output create both:
- html (bookdown_html_document2) and
- pdf (bookdown::pdf_document2) version
from single set of (R)Markdown and csv files. The reason that output is limited only to this formats is that usually this kind of reports are available for broad audience in pdf and rarely in html, nearly never in other formats. As there is a lot of formatting, to be as close as possible to original template that was created in some kind of Word family software, adding other output formats was pointless.
Current version of package supports:
- Express PRA (english)
- Express PRA for Invasive Plants (english)
- Express PRA - Ekspresowa Analiza Zagrożenia Agrofagiem (polish)
Polish version is a mix of classic PRA and PRA for Invasive Plants that is currently used in Poland in Institute of Plant Protection - National Research Institute. Package was tested under Ubuntu 16.10 with TeX Live 2018 and Ubuntu 18.04 with Tex Live 2017. Under Windows there are some chances that only html version will work.
Long story
Beginning of the idea
Some time ago, my boss asked me to make some tables with information on pest for our National Plant Protection Organization (or Ministry, don't remember right now). Usually if we are making this tables for few species we just copy paste the information from website. This time, however, it was over 80 species. The whole work was complicated, since some of this 'species names' were actually common names that were used for different 'scientific' species... All in all I decided that doing whole stuff manually will take ages... (meaning around 3-4 days of doing monkey level tasks AKA copy-pasting). Hopefully all necessary information comes from EPPO - our Regional Plant Protection Organisation. Even better they have REST API, SQL db, and easy to webscrap pages. It was easy to write a script that finished all the stupid work in no time.
This lead me to the conclusion - why we waste so much time each year in our work. Thus, after a while in spear time I re-wrote whole script into package - pestr - that automates extraction of information from different sources from EPPO Data Services. In the long run however I wanted to create automatic system that allows us to produce at least partially filled reports - Pest Risk Analyses. We make around 25 of them each year so the time saving is maybe not big, but it is definitely more pleasant to push some stupid copy-pasting work on the machine. Unfortunately I was not able to automatize everything till the submission deadline and some work (transforming data frames that are result of current pestr function into data frames that are used in pestrPRA templates), however it can be easily done wit 2 or 3 dplyr commands, e.g.
library('pestr')
create_eppo_token('<<your eppo token>>')
#vector of pest names to query db
pest <- 'Helicoverpa zea'
#connect to SQLite db
eppo_SQLite <- eppo_database_connect()
#get pest preferred name and eppocodes that will be used for other functions
pest_names <- eppo_names_tables(pest, eppo_SQLite)
#get pest categorization and transform table to template format
pests_cat <- eppo_tabletools_cat(pest_names, eppo_token)
cat_table <- pests_cat[[1]][[1]] %>%
select(c('nomcontinent','country','qlistlabel','yr_add'))
#get pest hosts and transform table to template format
pests_hosts <- eppo_tabletools_hosts(pest_names, eppo_token)
hosts_tab <- pests_hosts[[1]] %>%
rename(Comments = labelclass) %>%
mutate(Presence_PRA_area = 'Yes/no',Reference = '@eppo2018') %>%
select(full_name, Presence_PRA_area, Comments, Reference)
PRA Template making of...
What can be complicated when you make (R)Markdown document? Pretty everything... especially when you try to translate something that was created in Word (or other document WYSIWYG app) to Markdown that will compile to both pdf and html. And you have a lot of tables. And colors. And even more tables, colors, and some strange formatting stuff. And you need to provide instructions in comments that are easy to read and understand in both raw markdown and compiled files. You of course can ask why bother? And the explanation needs separate paragraph...
Why bother with making this...
Usually we work in groups. Most of people involeved in risk analysis are scientist and/or clerks with no to limited knowledge on programing, text processing, LaTeX etc. In consequence, up until now we were forced to use templates in *.doc format. This leads to several problems:
- everyone is using different OS with different text editor, which leads to huge mess in document formatting
- there is no serious version controll
- some people tend to use *.docx format which produces wrong structure when compiled to pdf
- there is ALWAYS problem with References structure. ALWAYS.
Keeping in mind that people who fill the template do not have enough skills to operate markdown documents, use knitr and kableExtra, etc. forced me to make template that is as easy as possible to fill by them. Thus, I decided that all the big complicated tables needs to be separeted into csv files that can be easily filled/updated via any spreadsheet software. However, formatting nicely looking tables for pdf and html output needs to be made separetely for each of the outputs. As we want to fill only one document not two, code for both tables is included and choosen via simple ifelse statement depending on which output is produced. There are two tricky parts when using kableExtra. First is that, when using non default latex template file you need to include latex packages used by kableExtra into preamble (as explained in documentation). Second is that standard citation via @ does not work in tables. I solved this problem with this simple snippet:
df_Latex <- df$Reference %>%
gsub('@', '', .) %>%
strsplit('; ') %>%
lapply(formatingCite) %>%
lapply(paste, collapse = '; ') %>%
unlist %>%
data.frame(References = .) %>%
bind_cols(Q6, .) %>%
select(-'Reference')
df_Latex$References[df_Latex$References == '\\citeauthor{}, \\hyperlink{ref-}{\\citeyear{}}'] <- NA
Other problematic thing for which I couldn't find simple and elegant solution is Summary (Abstract) in this template. In original template from EPPO Summary is kind of messy table on the first page of report BEFORE title, authors etc. With simple hacking latex template file it is easy to bring Summary before title, yet still it needs separate code for html and pdf version. Thus, I decided to have html version of abstract in index.rmd file and pdf version of abstract in abstract.md file - this is the only place where user needs to provide the same content in two different files for different outputs. I made table in pdf format in colors similar to orginal template, and for html version i decided to use colors form Bootstrap Cerulean theme.
Rest of customization was made by simple adjustments in latex and html templates for which you can easily find soultions on StackOverflow. All this lead to template that can be filled by a person who only need to know that citation is made with @, bold is made with ** and italics with *. In my opinion it is hard to simplify work for lay people more.
Finally, I also made translation into polish. This can be easily achieved with lang argument in YAML preamble which takes care of html version and by adding
\addto\captionspolish{%
\renewcommand{\partname}{Etap}%
\renewcommand{\abstractname}{}%
}
to preamble.tex. I think that there was no other important stuff with internationalization.
If you find something not clear or need explanation of some other stuff from templates please feel free to ask me ![]()
Working example
Just do it... yourself
pestrPRA is available from GitHub:
devtools::install_github('mczyzj/pestrPRA')
After instalation you can start working easily by choosing File > New file > RMarkdown > From template in RStudio. Remember to configure your build to use bookdown through Build > Configure Build Tools - set Project build tools to website and point Site directory to folder that contains template files. You also need to change the name of a rmd file that is identical to folder name to index.rmd. Than you can build both - html and pdf template with Build book button in Build tab.
Real life example
Real life example of filled template can be found in example repo - files are quite large, thus it is better when you download them and check on your PC. Please, keep in mind that I didn't include all the graphics and tables in appendix. You can compare documents build from pestrPRA templates with original document build from .doc template - ask me for link since new users cannot add more than two ![]()
- html version Helicoverpa_zea/_main.html
- pdf version Helicoverpa_zea/docs/_main.pdf
For lazy ones... some screenshots
- html and pdf abstract and text
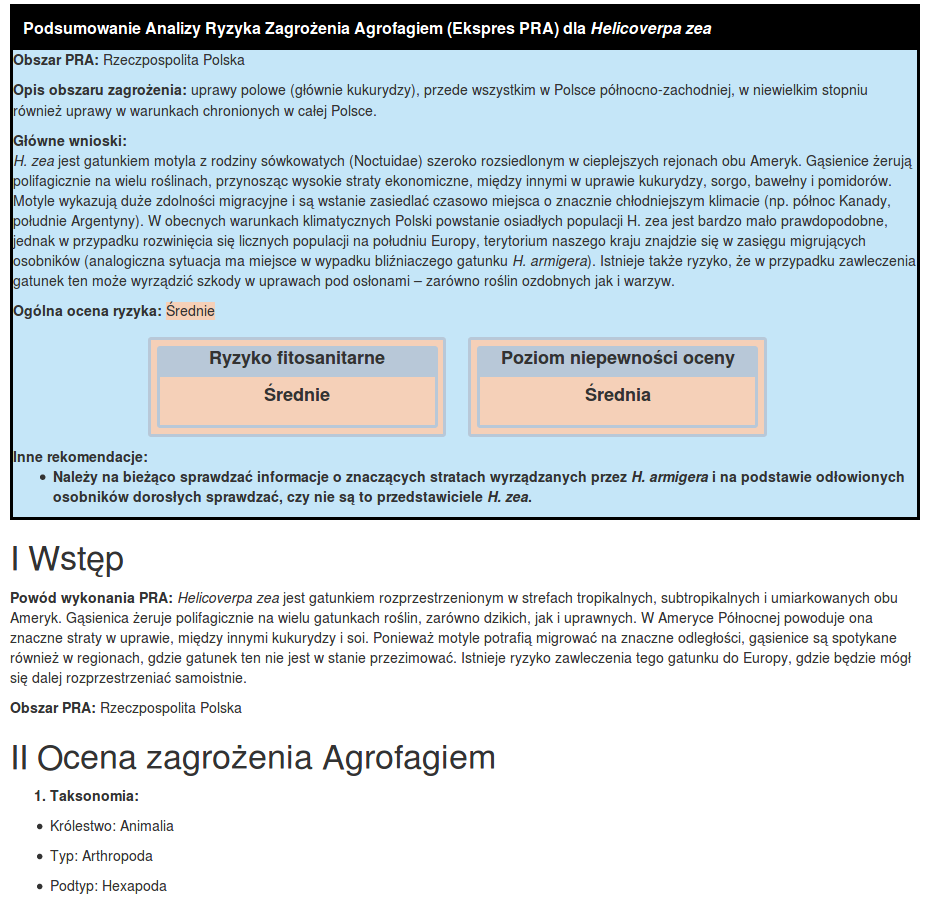
Where I can put more pics, as new users can add only one... ![]()
#Last but not least...
Of course there are many things to do in the future. Especially I need some help with making better layout, since my design skills are at best garbage. Also I need to wrap all the procedures to make ready to use tables and include them in pestr. Nonetheless, I hope you find my job interesting ![]()
Best,
Michal
 ), and am glad that you managed to automate your job. The customized HTML and PDF documents look great! Thanks for sharing!
), and am glad that you managed to automate your job. The customized HTML and PDF documents look great! Thanks for sharing!