Often, when I create an RMarkdown report, I like to integrate my code chunks with my write-up. For example, I would include the code chunks for pulling and cleaning data in with the section describing my dataset. I would include chunks related to running and checking a model in the section that describes that model, etc. This makes it easy for me to move from writing code in a notebook like fashion, to writing up a more polished report. It also makes it easy to sort through my RMarkdown file to answer questions / make updates related to a specific aspect of the report.
However, things are not as easy when the order of my code does not match the order of my write-up. This is a particular problem in the opening section of my document (abstract / executive summary) where I like to summarize my findings. I often want to reference a specific statistic or result that is not created in the code until end of my document. Rather than re-order my chunks, I have been “fixing” this issue by hard-coding a few values in the abstract section of my document. However, I know this is not best practice for creating a reproducible analysis.
Does anyone have suggestions or best practices about how to deal with this issue (reordering your code chunks, running external scripts, hardcoding a few pesky values, …), or any best practices in general for organizing a project whose results will need to be shared in a polished RMarkdown format?
If you need to evaluate your code in the bottom half of the document (because it produces output), then it effectively has to run twice. I don't see an easy workaround for that. On the other hand, if you break your display code into a separate chunk than your analysis code, it won't be an issue. Alternatively, if your code is deterministic and you don't mind it being evaluated twice, you can just live with it.
I run an external script, and it works pretty much as you'd expect:
Use the external script for all substantive analysis and to save a bunch of tables to .rdata or .rds.
Use the markdown doc to read the tables in and makes graphs, tables, etc.
Not sure if that's heretical as far as reproducible research norms go, but it seems transparent enough to me and it makes my code easier to read and maintain.
The ref.label option @nick pointed out looks handy, but I guess I still prefer separate docs rather than messing with analytical and publishing concerns all at once.
This wouldn't work in every case, but what I do is I save snapshots of my data or output as RDS files as key steps in my analysis. Then, I can load them earlier in analysis than they are generated or even in separate files. (The size of my reports generally leads me to use the modular solution described by Yihui on StackExchange)
Of course, this requires more care to make sure that these snapshots are getting appropriately refreshed as part of your workflow. However, this can also be beneficial if you don't want to run some very long computations every single time you "knit" (I typically do this by altering eval = TRUE / FALSE parameters.)
I find that RMarkdown documents can get pretty clunky when there's a lot going on with data munging, slow analysis steps, etc. This is especially so if I'm editing text and formatting and need to rerun render multiple times to get everything to look "just so". I prefer to use a Makefile to generate the various data files I want to run. Then I can read the data frames into my Rmd file and use that to focus on the text and formatting. I can also generate the rendered Rmd file from make as well.
I have a somewhat related question here.
I want to write an article in Rmarkdown, generating the graphs, but not showing any code whatsoever. That's fine, we can do that, that's done.
Now, if I wanted to include the R script at the bottom of the post (i.e. "for all interested, here is the code!"), how can I effectively do that?
I guess I could reference the rmarkdown file itself within the rmarkdown file (haven't tried it yet, will I break the space-time continuum?? ), but even if it works - the script already contains all the text that I don't need to display because people have already read it!
First, does anyone understand what I'm trying to say? And second: anyone knows how to achieve this: have a clean output followed by all code?
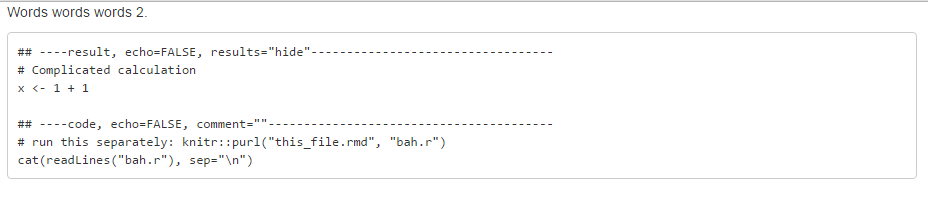
According to this SO answer, the trick is to reference all your code chunks at the bottom of your document with eval = FALSE in the chunk options. Then for all the chunks embedded in the document you would set echo = FALSE
@taras, see the ref.label technique I posted before. I made it somewhat convoluted due to the different context, but in your case (assuming I understand your case ), it works perfectly.
```{r result, echo=FALSE}
# Complicated calculation
x <- 1 + 1
# Outputted result
print(x)
```
Plain text between
```{r code, echo=TRUE, eval=FALSE, ref.label="result"}
```
This outputs:
## [1] 2
Plain text between
# Complicated calculation
x <- 1 + 1
# Outputted result
print(x)
@pavopax If I understand correctly, you include only visualization code in your .Rmd file, right? All the analysis code is in the code/ folder, and then (presumably) you load .rds files in your .Rmd file. Correct? Would it be possible to see an actual example, or are all your projects confidential? On one hand, I like your approach a lot because it makes debugging a lot easier, and rendering the .Rmd a lot faster. Also versioning is much better, as you noted. On the other hand, it kind of defeats the concept of literate programming...if one's main reason for using RMarkdown is results visualization and sharing, this is great, but I feel it wouldn't work for literate programming. I'd really like to see an actual example though - I may be wrong.
Indeed, all current analyses are confidential and not accessible . But I show some parts of a real current project in a quick gist.
You are correct! Rmd notebooks may include tables, and do include analysis results (like linear model results), when these analyses are not complicated or don't involve large data. I usually import CSVs (they are not large, and can then be shared easily), created with my munging code, as follows.
/code is usually for data munging, or "ETL" stuff: this is the messy and time consuming part. As you point out, .R files are easier to debug, version control, and collaborate on (using github), and then I just import the derived datasets into the Rmd notebooks, which are lean and run quickly.
This is a living workflow, which works well for me and my stakeholders and that is why it exists.
However, I know lots of team members who write long Rmd notebooks which include everything: data munging, outputs, results, etc, following the literate programming paradigm.
@pavopax Thanks! It's very clear now. I was initially fascinated by literate programming, but I'm gradually moving to an approach similar to yours. Keeping the complex codes outside RMarkdown makes things easier.
Generally I try (and often fail) to keep the html files really short, i.e. one task per file and save all the created objects (i.e. data_frames, models, plots) as .rds files. This give me a clear (and hopefully reproducible) workflow of where, and how, objects were created.
I then create summary pdf documents and directly load the reuslts I want into the report. e.g.
Do you not like the code folding option with hide turned on? The user can click "show all" at the top of the page to read the report with code, or click on any given chunk to see code for that section only.
 ), but even if it works - the script already contains all the text that I don't need to display because people have already read it!
), but even if it works - the script already contains all the text that I don't need to display because people have already read it!
 ), it works perfectly.
), it works perfectly.