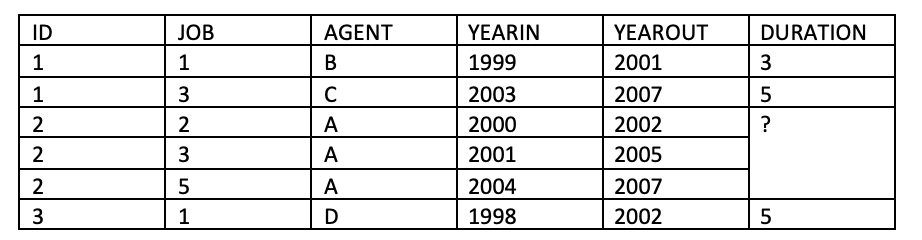
For these data, each AGENT has complete overlap, so I haven't taken this any further.
# functions
find_overlaps <- function(x) {
# begin helper functions
# identify agents
id_agents <- function(x) unique(x$AGENT)
# detect if a pair of rows overlap
is_overlap <- function(x,y) length(intersect(spans[x][[1]],spans[y][[1]])) > 0
# create subsets consisting of a single agent
get_agent <- function(x){
agent = dat[dat$AGENT == x,]
agent = agent[order(agent$YEARIN),]
as.matrix(agent[4:5])
}
# list of all the years included in each row
get_spans <- function(x) apply(x,1,make_span)
# for each row create a list of all years from YEARIN to YEAROUT
make_span <- function(x) x[1]:x[2]
# all combination of rows taken two at a time
find_tests <- function(x) combinat::combn(1:length(x),2)
# end helper functions
spans = get_spans(get_agent(x))
the_tests = find_tests(spans)
apply(the_tests,2,is_overlap)
}
# data
dat <- data.frame(
ID =
c(2, 2, 2, 2, 7, 7, 15, 18, 18, 18, 18, 18, 18, 20, 20, 20, 21),
JOB =
c(1, 2, 7, 8, 1, 1, 1, 1, 2, 4, 2, 3, 2, 3, 4, 6, 3),
AGENT =
c("A", "A", "B", "B", "B", "A", "A", "D", "D", "D", "A", "A", "B", "C", "C", "C", "A"),
YEARIN =
c(1998, 1996, 1979, 1978, 1973, 1979, 1975, 1980, 1980, 1982, 1978, 1976, 1976, 1988, 1996, 1985, 1989),
YEAROUT =
c(2009, 2000, 1979, 1982, 2007, 2007, 2009, 1981, 1985, 1987, 1979, 1982, 1979, 1993, 2002, 2000, 1992))
# main
lapply(unique(dat$AGENT),find_overlaps)
#> [[1]]
#> [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
#> [16] TRUE TRUE TRUE TRUE TRUE TRUE
#>
#> [[2]]
#> [1] TRUE TRUE TRUE TRUE TRUE TRUE
#>
#> [[3]]
#> [1] TRUE TRUE TRUE
#>
#> [[4]]
#> [1] TRUE TRUE TRUE
Interpretation: The return value is a list of AGENTS, each of which has more than one record (row). For each agent, the Booleans return the result of comparison of each combination of each AGENT with each other agent. TRUE indicates overlap. FALSE, if there were any indicates the absence. Missing is a function to return the earliest and latest of the overlapping years.