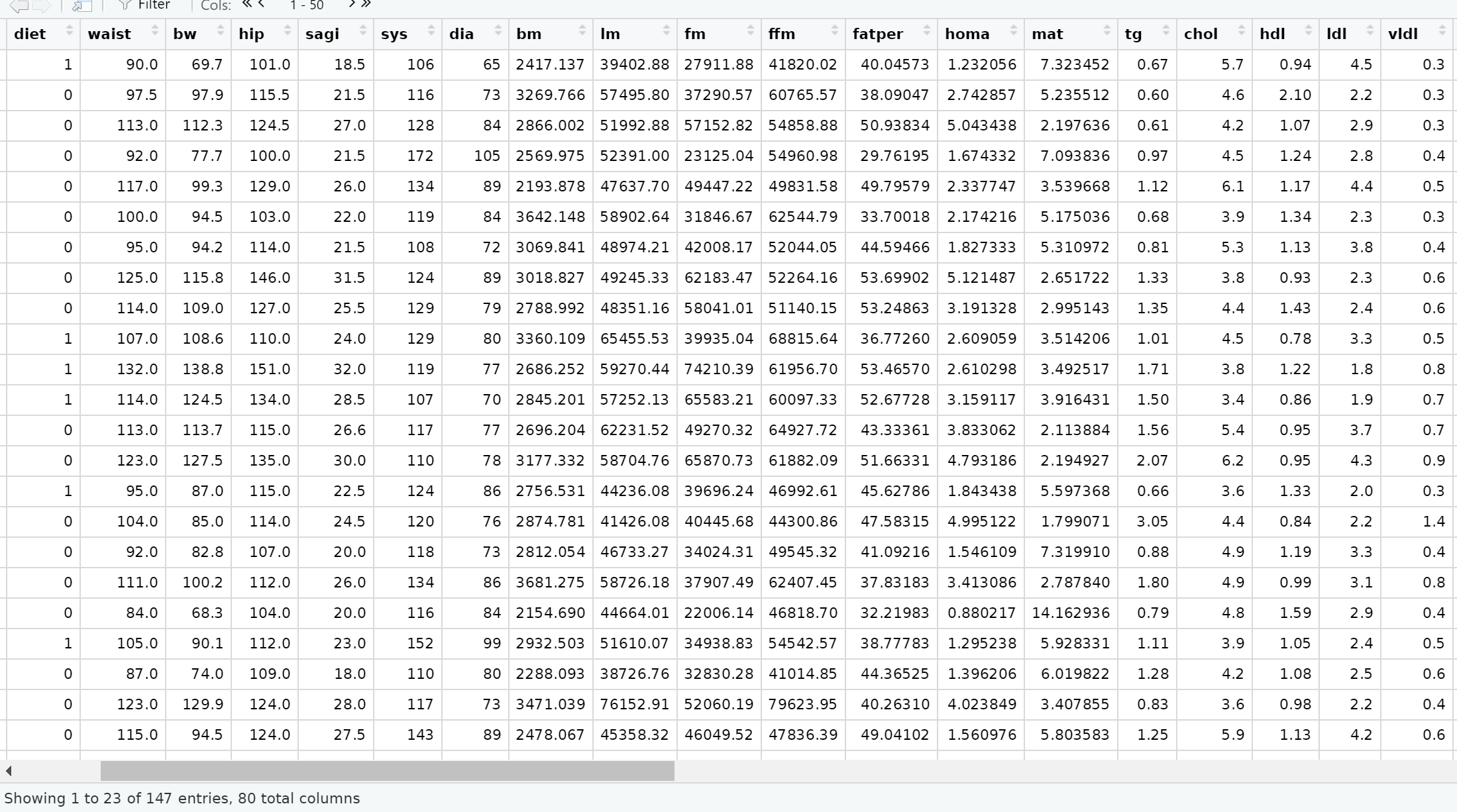
I want to create a column with p-values in order to compare every columns (biomarkers) for the two diets(NND (n= 91) and ADD (n= 56)), but i don't know how to do it.
Screenshot of the data called NordicDiet_baseline:
I have used the following code to filter out NND (diet = 0) and ADD (diet = 1) and calculated means and sd for every column but I don't know if that's even relavent to my question:
This isn't so much a how problem as a what problem. What is it that we want to know about the results reported here? Differences between diet with respect to BMI? Between sex and waist? Do we want to know whether any or all of these variables reflect changes with respect to visit? Whether any two variables have different means or medians?
We probably don't need to do anything to do in order to know that BMI is correlated with weight and height—it should be perfectly correlated because that's how it's defined. (Although that might be a check on data integrity.)
I want to make a new column with the p value between every biomarkers for ADD (diet = 1) and NND (diet = 0) diet for instance weight ADD and NND, hip ADD and NND... vldl ADD and NND and so on - i just wondered if the was a way to do this for everyone at once instead of doing a t.test for every single biomarkers