I absolutely agree, I was a moderator on other sites in the past and I understand where the moderator is coming from.
I was sort of desperate to ask my question, and without an ability to comment, and without the time to go through Stack Exchange and find questions I can answer, and then wait for points to come in - this was my equivalent of screaming into the void.
While I hear you, I have to say that the mechanism is a little bit upside down. Beginners come to SO for answers, helping others is not on their immediate agenda at that time. I think it's gotta be "Come for the answers, stay for the contribution" approach where at first a newbie gets a carte blanche, but the more time you spend on SO, the more is expected of you. (By the way, perhaps this is exactly how it works. I don't know. With all sincerity - I haven't spent too much time reading about SO and details of how it functions, and it is definitely not in their tour of the website)
I disagree with this (respectfully, of course), and I actually just did a little write-up on how I did/why I think I benefitted from the "association bonus" thing.
The aspect of what you're saying that would have been very difficult for me to empathize with before spending time answering questions elsewhere, is that there's an "abuse" (not in the violent sense of the word, in the not-using-as-intended sense) issue with a lot of drive-by poor-quality question asking (all of this is ~better described in the post I wrote). The Help Vampire thread has advice on the ways SE/SO tries to deal with this, and I by no means think it's perfect. But, if new users had carte blanche, I don't think the site would be the resource it is today (I have no Bayesian counterfactual, but, for all its shortcomings, the structure of SO is pretty rigorously discussed/thought through).
To show why it's not that way, I point you back to an important sentence from Frank:
Weird as it may sound, SO is not about helping you answer your question (directly, anyway). Instead, the tour tells you
With your help, we're working together to build a library of detailed answers to every question about programming.
i.e. SO is about helping build a resource that answers your question. That explains exactly why SO is structured as it is, e.g. why asking a question is hard:
At Stack Exchange, we insist that people who ask questions put some effort into their question, and we're kind of jerks about it.
But for good reason: we're not-so-subtly trying to help you help yourself, by teaching you Rubber Duck problem solving.
Incoming questions are a universal constant, all around us in countless billions. But answers — truly brilliant, amazing, correct answers — are as rare as pearls. Thus, questions are merely the sand that produces the pearl. If we have learned anything in the last three years, it is that you optimize for pearls, not sand.
A repository of high-quality answers is the goal because
It is probably getting difficult to imagine what a programmer's life was like BSO (Before Stack Overflow, prior to 2008). Back when Joel Spolsky and Jeff Atwood were still programming for a living. And ran into the same problem that everybody was experiencing back then, finding help to get you unstuck to solve a programming problem was hard work back then.
You would be lucky if you found a FAQ or knowledge base article on a vendor's site. Low odds for that after ~2000, vendors started to rely on their forums as their primary way to provide support.
If you would not be so lucky, and very common, you'd hit the paywall of a sleazy web site like expertsexchange.com. A web site that did more than any other to formulate the founders' ideas of what a useful site should look like. They took answers from volunteers but charged a subscription fee for anybody to look at those answers.
But most commonly, you'd have to dig through hits for Usenet posts and programmer forums that touched on the same subject. But maddeningly poorly curated, you'd have to sift through hundreds of pages worth of chit-chat and people calling each other names. Often not providing an answer at all. Or resembling an answer but not in any way an accurate one, just blind guesses that you could only weigh by having to read on for the "it doesn't work!" follow-up posts.
So Spolsky and Atwood set out to do something about it. Core ideas where a site that's strictly Q+A, no chit-chat or discussion, just questions and answers strictly separated. And a means to get the true answer to the top efficiently by voting. And strongly avoiding a glut of duplicate questions to limit the amount of Google hits anybody has to scan. And, after a fat year, focusing only on true programming problems.
Very successful of course, SO was a strong magnet for subject experts that were pretty happy about the focus, providing excellent answers. Most programmers that asked a question could get a great answer in less than 10 minutes. It quickly overtook any other web site in Google ranking, nobody else comes close.
The question that that was designed to answer and its other answers are a gold mine for understanding SO, and are well worth a deeper look:
The goal of SO provides a justification for Baptiste's point, as well:
If the goal of the community is similar to SO, that's correct: there are no high-quality answers without capable answerers. If the goal is different—likely, or Discourse is an odd choice—experts may or may not be necessary (to be a gathering place for new useRs to commiserate is a valid goal), though it's undeniable experts would make the community considerably more valuable.
One under-sung option for SO rep (imho) is that, once you’ve gotten 200 points on any of the SE sites, you automatically get 100 on the others. I think answering questions on the other sites also teaches you quite a bit about helpful question-asking, and gives you empathy for both sides of the Q&A. Personally, I did this through WebApps2 and English, I can’t remember which was first, but there are a ton of SE1 sites to choose from.
I just saw a question on this site (which was answered) but was probably more appropriate for SO. I'd be concerned that over time the same sort of coding questions come up here again and again - something that SO can gatekeep
Probably nobody has time on their hands but what might be useful here would be a daily list/link of new questions on SO related to RStudio e.g tidyverse, RMarkdown, leaflet etc.
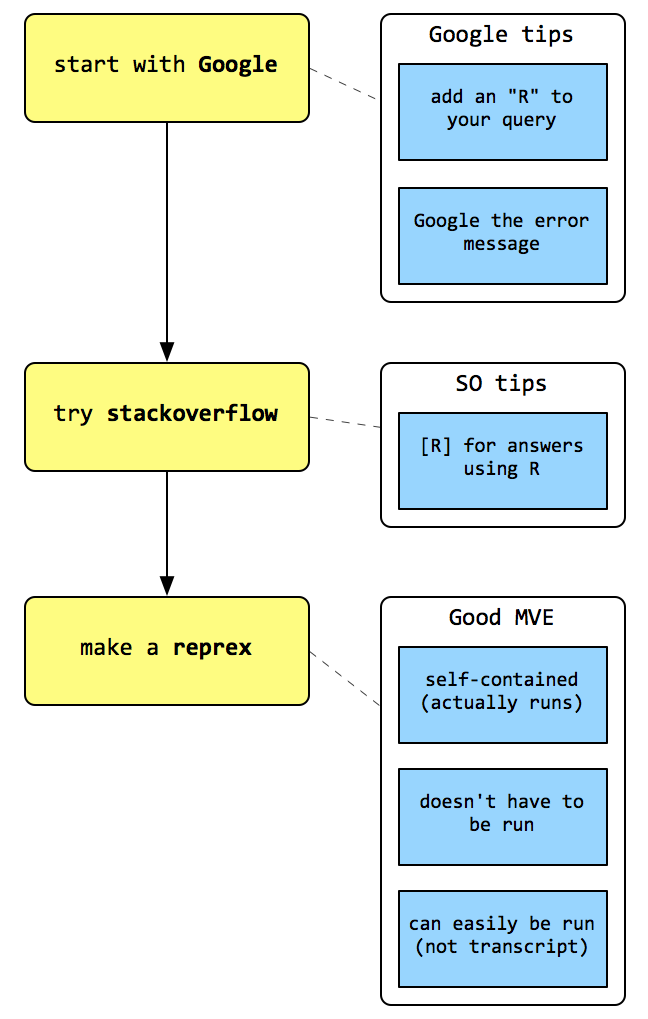
If I were to summarise it visually (and add a dash of my poorly-worded versions of @jennybryan's description of good reprex-ing from the rOpenSci community call) it might look something like this…
I don't think this is a complete flow chart of how to get help. There are elements of getting help that might be outside the scope of R4DS— perusing GitHub issues, this community site (which, AFAIK, didn't exist when the book went to print), etc., and I don't think it was intended as an exhaustive list. However, I think it might be worth thinking about how we could flesh something like this out a bit more…or adapting it to certain contexts (e.g. @jessemaegan, there are parts of the r4ds learning community that might fit in here, but that aren't universal).
But part of what I like about this site, as a complement to SO, is ... what if we don't have to gatekeep and stress out so much re: duplicates? Maybe it's ok that certain questions come up repeatedly because it's always new to someone? In the limit -- all questions are very elementary and repetitive -- that would, of course, be bad. If that seems to be a real problem, perhaps there's a way to tag or relocate such questions.
This is a really good point, and I think it actually relates to what @pssguy is describing re. question comparisons— I like that the comparisons exist on SO, however the comparisons are only based on certain variables. And, for a beginner (or anyone not familiar with the vocabulary around the problems that come up) two similar questions might not actually seem to be the same thing.
It's also possible that they aren't the same thing (because of time and OS changes, or things that no longer exist, etc.), but that can be an intimidating thing to declare on SO: "My very similar question is definitely different from all the others."
is (in my mind) a bold statement in the world of SO.
I'ld like to add to this discussion that asking questions about topics that touch best practices in coding or also other programming languages (i.e. webdevelopment stuff for shiny), might result in much more emphatic answers, if people share the same background -> specialist in R, but maybe not in computer science in general.
SO doesn't really gatekeep; anybody is free to ask any question. Questions may get closed (and deleted if they are spam/useless), but SO faces a stream of questions without reprexes, duplicates, and more. Some get fixed, some get closed, and some unfortunately become tumbleweeds, which is really worse than getting closed as a duplicate, as the asker never gets an answer.
As far as this site goes,
When a question has a good reprex and isn't a very common one, the community should perhaps respond, "Hey, this is a good question! You should ask it on SO," which gives the asker a confidence bump and makes it easier for people to find the question later.
If the question is a very common one (e.g. one of SO's r-faqs), linking to the canonical question on SO, e.g. for joins or long to wide form or summarizing multiple variables or making lists of data.frames can be really useful. There's not really a point in deduplicating here, but there is a point in directing the asker to a set of solid answers. Translating the answer to their context (i.e. answering) is nice as well, but sometimes pointing askers to the right resource is actually all they really need.
Other questions (opinion-based, looking for tools, etc.) fit more neatly here than SO.
The SO API is good, and these could be nailed down to a particular set of parameters (say top 10 Qs and As with most votes on a given set of tags), so this wouldn't necessarily be complicated if there's interest. The top questions usually get answers, though, so they're more use for reading than answering, if that's the intent.
If bold, it's not uncommon. For it to be useful, it has to be followed with a distinction, though. I see a lot of XY questions that make that claim but don't illustrate a difference in their reprex, and the difference is only teased out after lots of comments (if the question even gets that far).
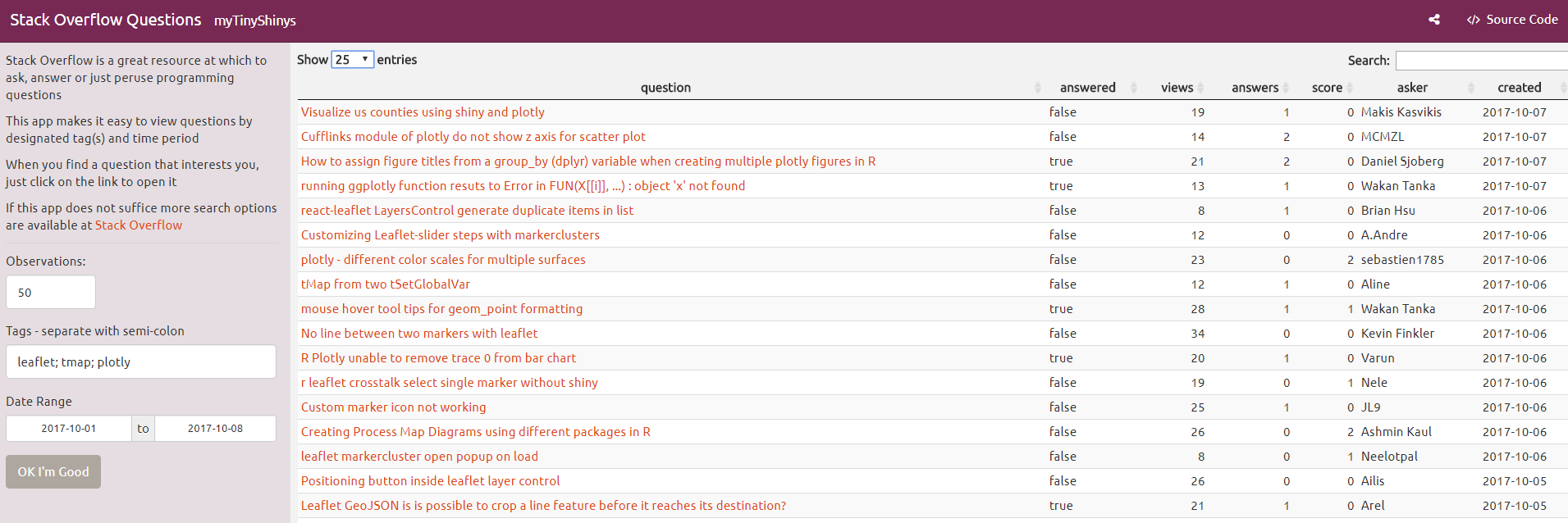
Cool! Now it would be nice if I could click the links in the link column when viewing the top_tidy_qs dataframe. I guess I'll look for the RStudio feature request thread and post it there!
I've seen that in iTerm2 (including when running R interactively), in which you can click on any URL/file path/email address/etc. when holding CMD, but I suspect implementing it was a lot of work. For now, utils::browseURL works, e.g.
Looks good, but it'd be more useful to be able to query the top-scoring questions. Actually, it's sometimes more interesting to look at the top-scoring answers, which tend to outscore their questions significantly.