Hi all,
I am new to R. I am analyzing export Wh, data for my project.
Original csv file (org_data.csv) that I m analyzing can be found in this link:
[https://drive.google.com/open?id=12a3EfbSKKuPRAYUC-c58tbnBaiVlweVI ]
In the original csv file, there are 1,584,823 total records, with 157 meters.
Recorded from 1-Oct-2015 00:00:00 to 31-Mar-2016 23:59:59
In the csv file, there are three columns: local minutes, dataID, meter_value.
- Local minutes is formatted with “yyyy-mm-dd hh:mm:ss-UTC
time offset”. - dataID represents the ID number for each 157 meter,
- meter_value represents the export Wh
Quick view of original csv file, as below:
localminute,dataid,meter_value
2015-10-01 00:00:10-05,739,88858
2015-10-01 00:00:13-05,8890,197164
2015-10-01 00:00:20-05,6910,179118
2015-10-01 00:00:22-05,3635,151318
2015-10-01 00:00:22-05,1507,390354
2015-10-01 00:00:29-05,5810,97506
2015-10-01 00:01:18-05,6910,179118
2015-10-01 00:01:34-05,6910,179118
2015-10-01 00:01:38-05,5810,97506
2015-10-01 00:01:43-05,4352,218216
2015-10-01 00:01:46-05,484,99298
2015-10-01 00:01:56-05,1718,161076
2015-10-01 00:01:58-05,1714,147048
We can observe that, export Wh are recorded every minute for each dataID, but there are only 6 export Wh records for 2015-10-01 00:00:xx. There are missing records for remaining 151 meters.
Same goes for 2015-10-01 00:01:xx, there are only 7 meters recorded in the csv file. 150 meters' records are missing.
Objective of this project is to write algorithm to fill these missing data for 56 meters. Hence, there should have 56 records for each minutes starting from 1-Oct-2015 00:00:00 to 31-Mar-2016 23:59:59.
the dataID that I would like to predict missing data, are as below:
9729,9639,9295,9134,8890,8829,8156,7989,7674,7429,
7287,7117,7030,7017,6910,6673,6412,5892,5814,5810,
5785,5403,5193,5131,4998,4514,4031,4029,3893,3778,
3527,3367,3310,2461,2129,2094,2072,2034,1801,1791,
1790,1718,1714,1589,1507,1283,1185,1086,871,739,
484,483,252,94,77,35
Before data prediction, I have done:
- data importing (read csv file in R-studio)
- data processing: convert “localminute” to “datetime” type and “dataid” converts to “factor” type.
- data visualization: plot all the dataID using facet function
This is the 56 meters of existing data plot. Existing data, most of all meters are linearly increasing. Based on these existing data, I have to write algorithm for missing data prediction algorithm.
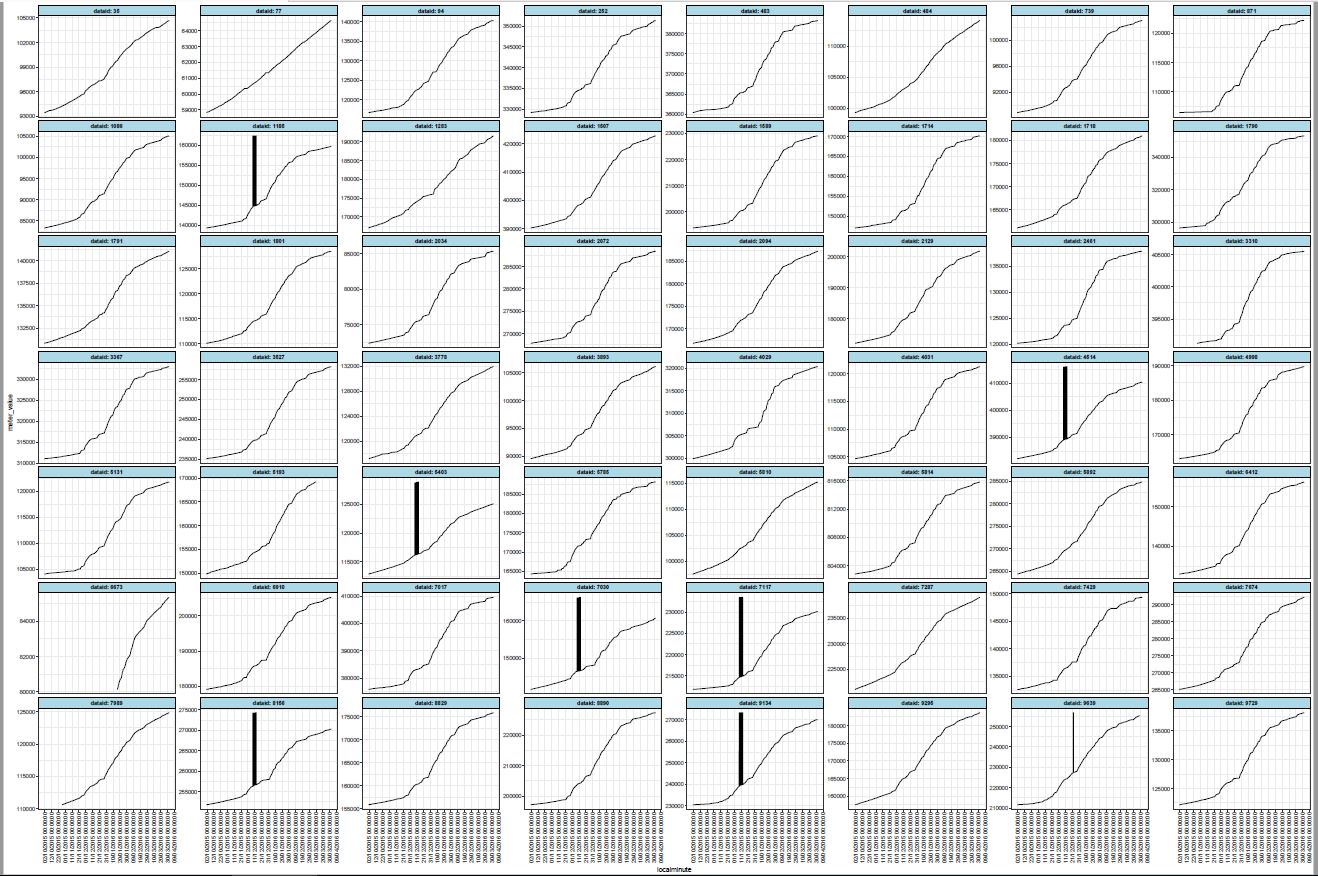
Out of these 56 meters, there are some spikes in certain meter IDs, for december. These spikes (I assume noisy data), will be another issue. Hence,I also would like to ask, how should I predict for missing data of those meterID that has spikes in existing data.
