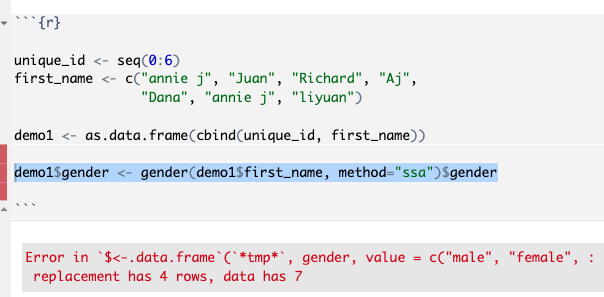
Hello, I attempted to extract gender information from the first name using gender package in R. I tried both 'ssa' and 'genderize' for argument method.
For ssa, it uses names based from the U.S. Social Security Administration baby name data. Therefore, if the name does not include in ssa, it will return the error as shown below.
I know this is because 'annie j' does not include in the name dataset, ssa. Any suggestions or advice to fix it?
Really appreciate your help and reply.
To have a data.frame of all names you wanted to test, and their gender results (and gaps where gender was not detected) you would perform a Left Join with your original data.frame on the left and the shorter gender results data.frame on the right.
dplyr package has a function that helps you do this; the left_join() function
x is d y the the object to be created, which isn't clear from the description f is the function to transform x to y and may be composite
Often the most difficult part is clearly having in mind the content of y. In the example below, I assume a data frame with variables unique_id, first-name and gender. Because ssa does not recognize space separated first names gender() will return only single-word names, so f should in addition to single word names should trim multiple word names to a single word to recheck. Single word names with no match should be included with gender of NA. I compose f to illustrate this stepwise for clarity.
library(gender)
(d <- data.frame(
unique_id = 0:9,
first_name = c("mary ann", "billy bob", "norma rae",
"jim bob","Juan", "Richard", "Aj",
"Dana", "annie j", "liyuan")))
#> unique_id first_name
#> 1 0 mary ann
#> 2 1 billy bob
#> 3 2 norma rae
#> 4 3 jim bob
#> 5 4 Juan
#> 6 5 Richard
#> 7 6 Aj
#> 8 7 Dana
#> 9 8 annie j
#> 10 9 liyuan
(keepers <- gender(d$first_name, method="ssa"))
#> # A tibble: 4 × 6
#> name proportion_male proportion_female gender year_min year_max
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl>
#> 1 Aj 0.988 0.0119 male 1932 2012
#> 2 Dana 0.202 0.798 female 1932 2012
#> 3 Juan 0.992 0.0084 male 1932 2012
#> 4 Richard 0.996 0.0037 male 1932 2012
(unfound <- d[-which(d$first_name %in% keepers$name),])
#> unique_id first_name
#> 1 0 mary ann
#> 2 1 billy bob
#> 3 2 norma rae
#> 4 3 jim bob
#> 9 8 annie j
#> 10 9 liyuan
unfound$first_name <- sub(" .*$","",unfound$first_name)
(one_name <- gender(unfound$first_name, method="ssa"))
#> # A tibble: 5 × 6
#> name proportion_male proportion_female gender year_min year_max
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl>
#> 1 annie 0.0053 0.995 female 1932 2012
#> 2 billy 0.988 0.0119 male 1932 2012
#> 3 jim 0.997 0.0034 male 1932 2012
#> 4 mary 0.0036 0.996 female 1932 2012
#> 5 norma 0.0051 0.995 female 1932 2012
(lost <- setdiff(unfound$first_name,one_name$name))
#> [1] "liyuan"
(combined <- rbind(keepers,one_name))
#> # A tibble: 9 × 6
#> name proportion_male proportion_female gender year_min year_max
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl>
#> 1 Aj 0.988 0.0119 male 1932 2012
#> 2 Dana 0.202 0.798 female 1932 2012
#> 3 Juan 0.992 0.0084 male 1932 2012
#> 4 Richard 0.996 0.0037 male 1932 2012
#> 5 annie 0.0053 0.995 female 1932 2012
#> 6 billy 0.988 0.0119 male 1932 2012
#> 7 jim 0.997 0.0034 male 1932 2012
#> 8 mary 0.0036 0.996 female 1932 2012
#> 9 norma 0.0051 0.995 female 1932 2012
combined$name <- casefold(combined$name)
combined <- combined[c(1,4)]
combined <- rbind(combined,c(lost,NA))
colnames(combined)[1] <- "first_name"
result <- dplyr::left_join(d,combined)
#> Joining with `by = join_by(first_name)`
result$gender <- combined$gender
result
#> unique_id first_name gender
#> 1 0 mary ann male
#> 2 1 billy bob female
#> 3 2 norma rae male
#> 4 3 jim bob male
#> 5 4 Juan female
#> 6 5 Richard male
#> 7 6 Aj male
#> 8 7 Dana female
#> 9 8 annie j female
#> 10 9 liyuan <NA>