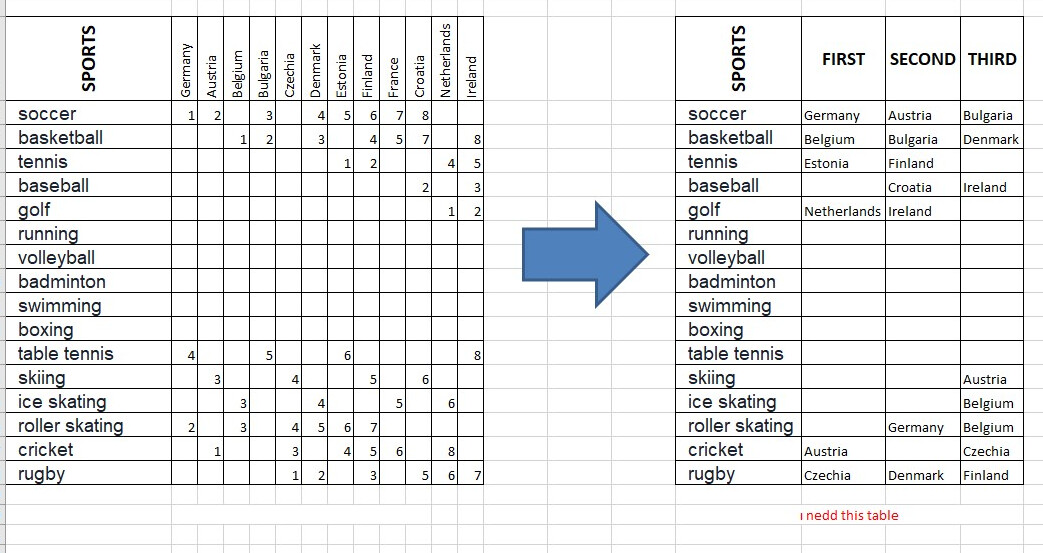
I'm not understanding how tidyr::pivot_longer and tidyr::pivot_wider don't solve this problem... Isn't this what you are looking for?
library(tidyverse)
#> Warning: package 'ggplot2' was built under R version 4.1.3
#> Warning: package 'tibble' was built under R version 4.1.3
#> Warning: package 'tidyr' was built under R version 4.1.3
#> Warning: package 'dplyr' was built under R version 4.1.3
#> Warning: package 'forcats' was built under R version 4.1.3
df <- data.frame( # N.B. I made one correction to the data so that Czechia's Soccer Value was NA,
# just like it is in your screenshot.
SPORTS=c("soccer", "basketball","tennis","baseball","golf","running","volleyball","badminton","swimming","boxing","table tennis","skiing","ice skating","roller skating","cricket","rugby"),
Germany=c(1, NA, NA, NA, NA, NA, NA, NA, NA, NA, 4, NA, NA, 2, NA, NA),
Austria=c(2, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 3, NA, NA, 1, NA),
Belgium=c(NA, 1, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 3, 3, NA, NA),
Bulgaria=c(3, 2, NA, NA, NA, NA, NA, NA, NA, NA, 5, NA, NA, NA, NA, NA),
Czechia=c(NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 4, NA, 4, 3, 1),
Denmark=c(4, 3, NA, NA, NA, NA, NA, NA, NA, NA, 4, NA, 4, 5, NA, 2),
Estonia=c(5, NA, 1, NA, NA, NA, NA, NA, NA, NA, 6, NA, NA, 6, 4, NA),
Finland=c(6, 4, 2, NA, NA, NA, NA, NA, NA, NA, NA, 5, NA, 7, 5, 3),
France=c(7, 5, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 5, NA, 6, NA),
Croatia=c(8, 7, NA, 2, NA, NA, NA, NA, NA, NA, NA, 6, NA, NA, NA, 5),
Netherlands=c(NA, NA, 4, NA, 1, NA, NA, NA, NA, NA, NA, NA, 6, NA, 8, 6),
Ireland=c(NA, 8, 5, 3, 2, NA, NA, NA, NA, NA, 8, NA, NA, NA, NA, 7)
)
out <- df %>%
pivot_longer(
cols = !SPORTS,
names_to = 'country',
values_to = 'rank'
) %>%
filter(
is.na(rank) | # Need to keep the NAs to retain all the sports
rank <= 3
) %>%
pivot_wider(
id_cols = SPORTS,
names_from = rank,
values_from = country
) %>%
select(
-`NA`
) %>%
unnest(
2:4
)
#> Warning: Values from `country` are not uniquely identified; output will contain list-cols.
#> * Use `values_fn = list` to suppress this warning.
#> * Use `values_fn = {summary_fun}` to summarise duplicates.
#> * Use the following dplyr code to identify duplicates.
#> {data} %>%
#> dplyr::group_by(SPORTS, rank) %>%
#> dplyr::summarise(n = dplyr::n(), .groups = "drop") %>%
#> dplyr::filter(n > 1L)
out
#> # A tibble: 10 x 4
#> SPORTS `1` `2` `3`
#> <chr> <chr> <chr> <chr>
#> 1 soccer Germany Austria Bulgaria
#> 2 basketball Belgium Bulgaria Denmark
#> 3 tennis Estonia Finland <NA>
#> 4 baseball <NA> Croatia Ireland
#> 5 golf Netherlands Ireland <NA>
#> 6 skiing <NA> <NA> Austria
#> 7 ice skating <NA> <NA> Belgium
#> 8 roller skating <NA> Germany Belgium
#> 9 cricket Austria <NA> Czechia
#> 10 rugby Czechia Denmark Finland
Created on 2022-11-20 by the reprex package (v2.0.1)