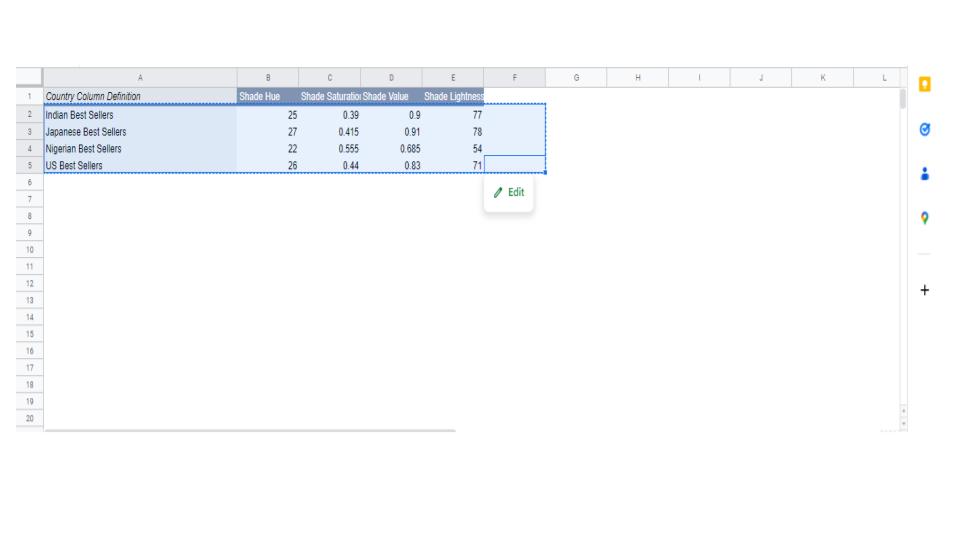
Hello,
I worked with a dataset in Google sheets, where I was able to use a pivot table to group data by countries and then find the median of four different columns of information (finding the median for each column). I used tht information to create a visual and it turned out pretty good.
As I am trying to learn R more, I decided to process the same dataset in R, and figure out how to duplicate the same things I did in Google Sheets. I was able to group data (countries) together and used the following code to get the median of each individual column:
As can be seen, the "US Best Sellers" row is practically empty, and the value that is included is way off from the median I got when I did this using Google Sheets. (Note: I just went back and looked at my dataset: some columns in the US Best Sellers section DOES have na, meaning there is a bunch of info missing. However, some of the US Best Sellers information IS filled in. I'm thinking R is throwing everything out because it doesn't know what to do with the data that says na. Is there a way to remove the na's? OR a way to convert the na's to zero (0) AND, if so, will that affect the calculation results?)
As for the other variables: Some are close but not exact, and some are just plain "off". I've posted below the values from Google Sheets for comparison:
I cannot read the image of your R results but I will take your word for it that the results differ. Can post a subset of your data that shows the problem? Running
dput(head(shades,50))
will give you output that you can post here and will allow others to use your data. Place a line with three back ticks before and after the posted output, like this:
```
output of dput
```
To deal with NA values, you can set the na.rm argument of median to TRUE
The code you have supplied is good but would be useful to see all the code and to see some sample data. A handy way to supply some sample data is the dput() function. In the case of a large dataset something like dput(head(mydata, 100)) should supply the data we need.
One thing I did notice is that you are using group_by() and then dplyr::summarise. group_by is in the *dyplyr pagkage as is summarise. Have you loaded dplyer using a library(dplyr) command?
Yes, I installed and loaded dplyr prior to running the code.
To your first point about using reprex: When I first joined this community, there was an introduction that included information about using reprex (for beginners). I've posted several questions to the community since then and I have to confess that it is I that got lazy and forgot all about reprex. I was hoping the bits of information I was providing would be enough to get some valuable feedback. Going forward, however, I will try to adhere to the guidelines and use (first learn to use) reprex so that it is easier on anyone trying to help me. Thanks for the reminder and I apologize for not doing what I should have been doing.
recall that R was invented, and has been extended and maintained, for use by statisticians for statisticians over a period 10 years longer than the existence of Google, beginning with the language S from Bell Labs in 1988. You've identified the source of the disconnect
median has an default argument of na.rm = FALSE because calculations involving NA evaluate to NA.
NA + 1
#> [1] NA
NA is not equivalent to 0 and shouldn't be treated as if it were.
When in doubt, it is safer to trust R assuming no errors in the code. Spreadsheets are cobbled together by computer programmers and they can give some peculiar and even nasty results sometimes. curious.math.table.pdf (127.5 KB)