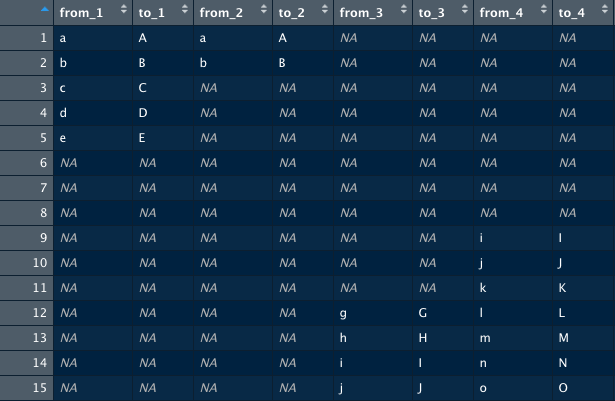
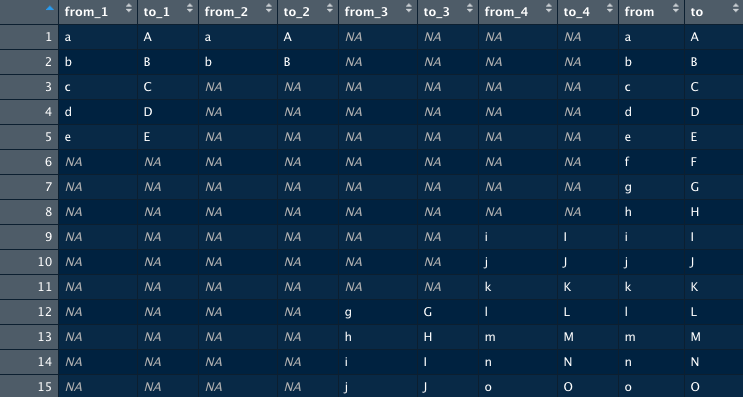
So, if I understand correctly your data at the start is a data frame containing columns named from_n and columns named to_n. Many of the values are NA.
For each row, you want to select the non-NA value across all the from_n columns where n is the highest, and the non-NA value from the to_n column with the largest n. Am I understanding correctly? On your second picture, rows 6, 7, and 8 have values f, g and h, I don't understand where they come from?
One way to do that is to use dplyr::coalesce() on each row. This function returns the first non-NA element. Since you want the last, you can use rev() before.
Of course, we have to treat to_* and from_* separately. So here is a solution, not a beautiful one, but it works:
dat = data.frame(from_1 = c(letters[1:5],rep(NA,10)),
to_1 = c(LETTERS[1:5],rep(NA,10)),
from_2 = c(letters[1:2],rep(NA,13)),
to_2 = c(LETTERS[1:2],rep(NA,13)),
from_3= c(rep(NA,11),letters[7:10]),
to_3 = c(rep(NA,11),LETTERS[7:10]),
from_4= c(rep(NA,8),letters[9:15]),
to_4 = c(rep(NA,8),LETTERS[9:15]))
dat_from <- dat[, startsWith(colnames(dat), "from_")]
dat_to <- dat[, startsWith(colnames(dat), "from_")]
new_from <- do.call(dplyr::coalesce, rev(dat_from))
new_to <- do.call(dplyr::coalesce, rev(dat_to))
cbind(dat, from = new_from, to = new_to)
#> from_1 to_1 from_2 to_2 from_3 to_3 from_4 to_4 from to
#> 1 a A a A <NA> <NA> <NA> <NA> a a
#> 2 b B b B <NA> <NA> <NA> <NA> b b
#> 3 c C <NA> <NA> <NA> <NA> <NA> <NA> c c
#> 4 d D <NA> <NA> <NA> <NA> <NA> <NA> d d
#> 5 e E <NA> <NA> <NA> <NA> <NA> <NA> e e
#> 6 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
#> 7 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
#> 8 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
#> 9 <NA> <NA> <NA> <NA> <NA> <NA> i I i i
#> 10 <NA> <NA> <NA> <NA> <NA> <NA> j J j j
#> 11 <NA> <NA> <NA> <NA> <NA> <NA> k K k k
#> 12 <NA> <NA> <NA> <NA> g G l L l l
#> 13 <NA> <NA> <NA> <NA> h H m M m m
#> 14 <NA> <NA> <NA> <NA> i I n N n n
#> 15 <NA> <NA> <NA> <NA> j J o O o o
Created on 2022-11-07 by the reprex package (v2.0.1)
Although now that I wrote it, coalesce() might not be that clear here. It might be easier to rewrite a new function:
dat = data.frame(from_1 = c(letters[1:5],rep(NA,10)),
to_1 = c(LETTERS[1:5],rep(NA,10)),
from_2 = c(letters[1:2],rep(NA,13)),
to_2 = c(LETTERS[1:2],rep(NA,13)),
from_3= c(rep(NA,11),letters[7:10]),
to_3 = c(rep(NA,11),LETTERS[7:10]),
from_4= c(rep(NA,8),letters[9:15]),
to_4 = c(rep(NA,8),LETTERS[9:15]))
last_non_na <- function(x){
non_na <- which(! is.na(x))
if(all(! non_na)) return(NA)
x[max(non_na)]
}
dat_from <- dat[, startsWith(colnames(dat), "from_")]
dat_to <- dat[, startsWith(colnames(dat), "from_")]
new_from <- apply(dat_from, 1, last_non_na)
new_to <- apply(dat_to, 1, last_non_na)
cbind(dat, from = new_from, to = new_to)
#> from_1 to_1 from_2 to_2 from_3 to_3 from_4 to_4 from to
#> 1 a A a A <NA> <NA> <NA> <NA> a a
#> 2 b B b B <NA> <NA> <NA> <NA> b b
#> 3 c C <NA> <NA> <NA> <NA> <NA> <NA> c c
#> 4 d D <NA> <NA> <NA> <NA> <NA> <NA> d d
#> 5 e E <NA> <NA> <NA> <NA> <NA> <NA> e e
#> 6 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
#> 7 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
#> 8 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
#> 9 <NA> <NA> <NA> <NA> <NA> <NA> i I i i
#> 10 <NA> <NA> <NA> <NA> <NA> <NA> j J j j
#> 11 <NA> <NA> <NA> <NA> <NA> <NA> k K k k
#> 12 <NA> <NA> <NA> <NA> g G l L l l
#> 13 <NA> <NA> <NA> <NA> h H m M m m
#> 14 <NA> <NA> <NA> <NA> i I n N n n
#> 15 <NA> <NA> <NA> <NA> j J o O o o
Created on 2022-11-07 by the reprex package (v2.0.1)
And here is a tidyverse approach, which is less efficient in this case, but could be easier to expand upon:
dat = data.frame(from_1 = c(letters[1:5],rep(NA,10)),
to_1 = c(LETTERS[1:5],rep(NA,10)),
from_2 = c(letters[1:2],rep(NA,13)),
to_2 = c(LETTERS[1:2],rep(NA,13)),
from_3= c(rep(NA,11),letters[7:10]),
to_3 = c(rep(NA,11),LETTERS[7:10]),
from_4= c(rep(NA,8),letters[9:15]),
to_4 = c(rep(NA,8),LETTERS[9:15]))
library(tidyverse)
last_non_na <- function(x){
non_na <- which(! is.na(x))
if(all(! non_na)) return(NA)
x[max(non_na)]
}
dat |>
mutate(row_number = row_number()) |>
pivot_longer(-row_number) |>
separate(name,
into = c("type", "n")) |>
group_by(row_number, type) |>
summarize(last_value = last_non_na(value),
.groups = 'drop') |>
pivot_wider(names_from = "type",
values_from = "last_value")
#> # A tibble: 15 × 3
#> row_number from to
#> <int> <chr> <chr>
#> 1 1 a A
#> 2 2 b B
#> 3 3 c C
#> 4 4 d D
#> 5 5 e E
#> 6 6 <NA> <NA>
#> 7 7 <NA> <NA>
#> 8 8 <NA> <NA>
#> 9 9 i I
#> 10 10 j J
#> 11 11 k K
#> 12 12 l L
#> 13 13 m M
#> 14 14 n N
#> 15 15 o O
Created on 2022-11-07 by the reprex package (v2.0.1)