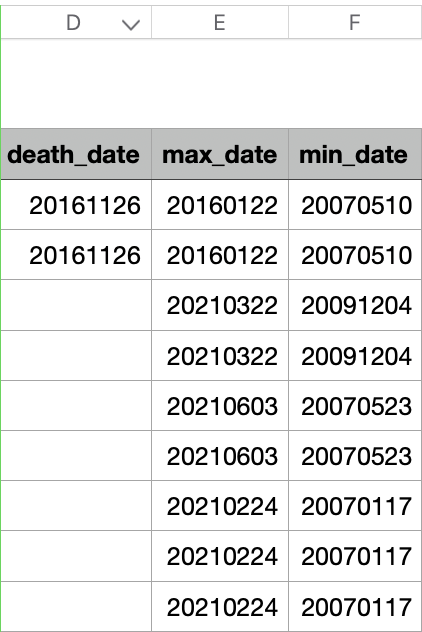
I have been using read_csv for reading tables and has worked like a charm so far. The column type inference is very nice, since it saves from having to do type conversions.
Except, for when it behaves a bit too naïve. Here is an example where some of date columns are misinferred as dbl:
Warning message:
“One or more parsing issues, call `problems()` on your data frame for details, e.g.:
dat <- vroom(...)
problems(dat)”
Rows: 15052 Columns: 286
── Column specification ────────────────────────────────────────────────────────────────────────────────────────────
Delimiter: ";"
dbl (285): min_date, max_date, ...
date (1): disease_start_date
I know what is triggering this: Columns like min_date and max_date have NA rows. Only disease_start_date is complete enough to infer the pattern.
Is there anything I can do to make the type inference a bit smarter?
Thanks!
Ok interesting , I must have missed a conflict warning.
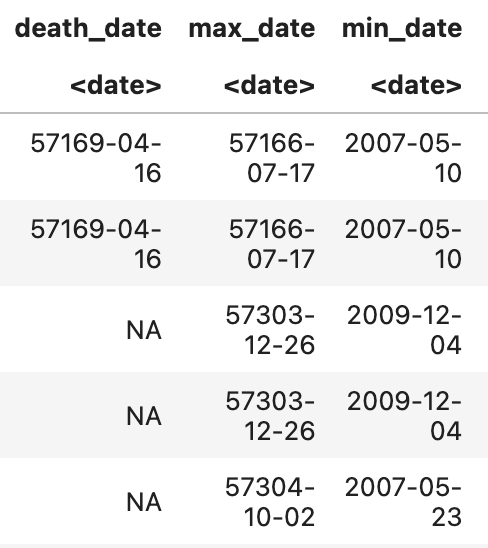
Now I think I am in the thick of it. My diagnosis is that the dbl-inference seems to happen if there are substantially more NA entries than actual values.
> sum(is.na(databank$min_date)) # min_date is inferred as date
> 14 # a mere 14 entries are NA
> sum(is.na(databank$death_date)) # death_date is inferred as dbl
> 12964 # Fortunately mortality is not too high, unfortunately that means many empty rows
I don't suppose there is any option to ignore NA while inferring the type?
> databank <- read_csv2(guess_max = 10000, col_types=cols(.default = col_character())) # Forcing character typing on all columns
> databank$min_date
> Strings of pattern: '20070510'...
> databank$death_date
> Strings of pattern: '20161126', or NA...
Yes, they are definitely the same. Seeing as MY issue is mostly with dates, perhaps I can force a conversion to col_date if the variable name contains date in it.
But I still don't understand why inference isn't able to gleam that these two are the same format. date is able to at least infer the first YYYYMMDD after all.