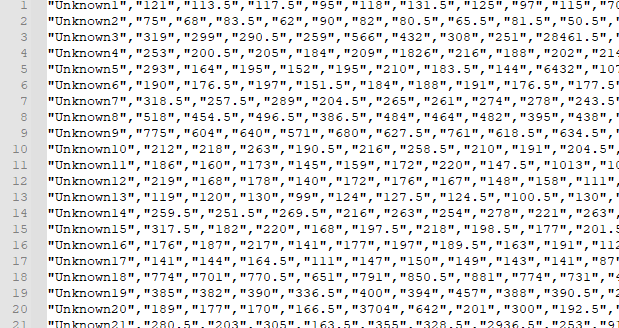So far I have always worked with CSV files that were ordered from top down
at the top the header and below the results.
but now I have a dataset in front of me that is sorted like this
so header and then in the same line the results.
How do I now read the file so that Unknow1, 2.... is my header line and the numerical values are the list belonging to the header line ?
My used read in code was:
data<-read.table(file="XXXXXXX", header=FALSE, sep=";", strip.white = TRUE, stringsAsFactors = TRUE, fileEncoding = "UTF-8", na.strings = "NA", skip=350, nrows=96,dec=",")
One way would be to read in the first column separate from the others and assign the column values (so your actual names) to the names attribute of the other data.frame which contains the values.
If the structure is always the same, you can wrap this method into a function and just apply it to every file you have to read. You can use list.files to get a character vector of all files in one directory and use lapply to create a list with the correctly formatted tables. So no additional work beside writing the function from this side.