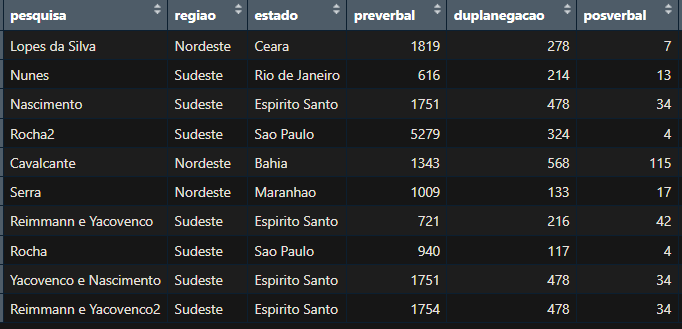
Hi everyone, so I have this csv from a few studies I'm analyzing, and I don't know how to merge the last 3 columns into one (a single variable with 3 levels) and then transform each number in a case (I managed to do this by creating another data frame with the function "countsToCases", but it only works for two variables, and I would like to add the other ones as well. Is it possible?
For example: a single case of [rocha2013, sudeste, Sao Paulo, negation].
I think your desired output can be achieved with pivot_longer() and uncount().
library(tidyverse)
# one row of your data
df = data.frame(
pesquisa = 'Nunes',
regiao = 'Sudeste',
estado = 'Rio de Janeiro',
preverbal = 616,
duplanegacao = 214,
posverbal = 13
)
out = df %>%
# reshape counts into one column
pivot_longer(cols = c('preverbal', 'duplanegacao', 'posverbal'),
names_to = 'type') %>%
# expand the counts into rows for individual cases
group_by(pesquisa, regiao, estado, type) %>%
uncount(value) %>%
ungroup()
out
#> # A tibble: 843 × 4
#> pesquisa regiao estado type
#> <chr> <chr> <chr> <chr>
#> 1 Nunes Sudeste Rio de Janeiro preverbal
#> 2 Nunes Sudeste Rio de Janeiro preverbal
#> 3 Nunes Sudeste Rio de Janeiro preverbal
#> 4 Nunes Sudeste Rio de Janeiro preverbal
#> 5 Nunes Sudeste Rio de Janeiro preverbal
#> 6 Nunes Sudeste Rio de Janeiro preverbal
#> 7 Nunes Sudeste Rio de Janeiro preverbal
#> 8 Nunes Sudeste Rio de Janeiro preverbal
#> 9 Nunes Sudeste Rio de Janeiro preverbal
#> 10 Nunes Sudeste Rio de Janeiro preverbal
#> # … with 833 more rows