Posit Community
How to remove some portion of all rows in a dataset
General
dplyr
,
read_csv
,
datatable
ridwna
March 18, 2022, 3:40pm
3
Screenshot_3
706×458 23.8 KB
@FJCC
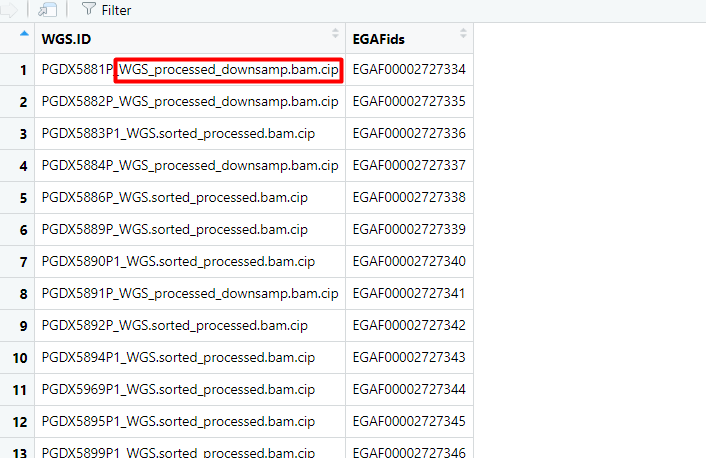
But I got another problem, on this data I want to remove this red squared portion from all rows, how can I do this?
How to convert a .map file into csv file in R
show post in topic