Hey guys, I have a 10 rows * 9 columns dataframe I am working with. However for the ninth row, I only want to keep the value in the first column and replace it with NA for the other 8 columns. Any ideas on how to do that? Btw the columns and rows have names at are not just numbers, but this shouldnt change anything right? Its just ["column name"] instead of [column number] for example.
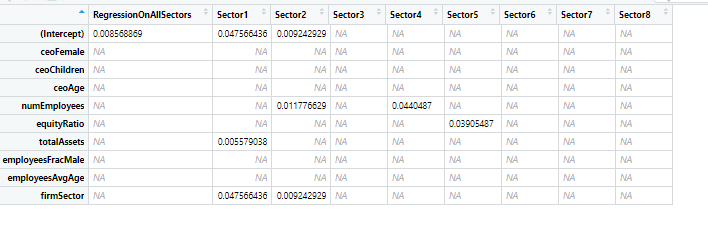
I attached a picture of how my dataframe looks. Dont get confused that in the first Column its already NA. I also want to apply what i am asking for on other similar datasets where the value of firmSector in 1st column is not NA.
Thank you guys in advance