This is a problem in regex design to find what common pattern the variable results have. They can't be split consistently on space or (. So, the results must be parsed to find the various patterns to be applied. Without a reprex. See the FAQ it's unlikely that the screenshot alone will draw much help because of the friction of having to transcribe. Can you provide a reprex and your take on how the results column values differ in pattern?
A way to address this problem is to clean the text first and then use tidyr::separate(). I'm going to give you an example with just the line you mentioned since the link you provided doesn't inspire much trust (it is not very likely people are going to download it).
library(tidyverse)
# Sample data in a copy/paste friendly format, use your own data frame instead
sample_df <- tibble::tribble(
~sample_text,
"Acute respiratory failure (2d - Fatal - Results in Death, Caused/Prolonged Hospitalisation),"
)
sample_df %>%
mutate(sample_text = str_replace(sample_text, "\\(", "- "),
sample_text = str_remove(sample_text, "\\),")) %>%
separate(sample_text,
into = c("Reaction_List_PT", "Duration",
"Outcome", "Seriousness_criteria"),
sep = " - ")
#> # A tibble: 1 × 4
#> Reaction_List_PT Duration Outcome Seriousness_criteria
#> <chr> <chr> <chr> <chr>
#> 1 Acute respiratory failure 2d Fatal Results in Death, Caused/Prolonged…
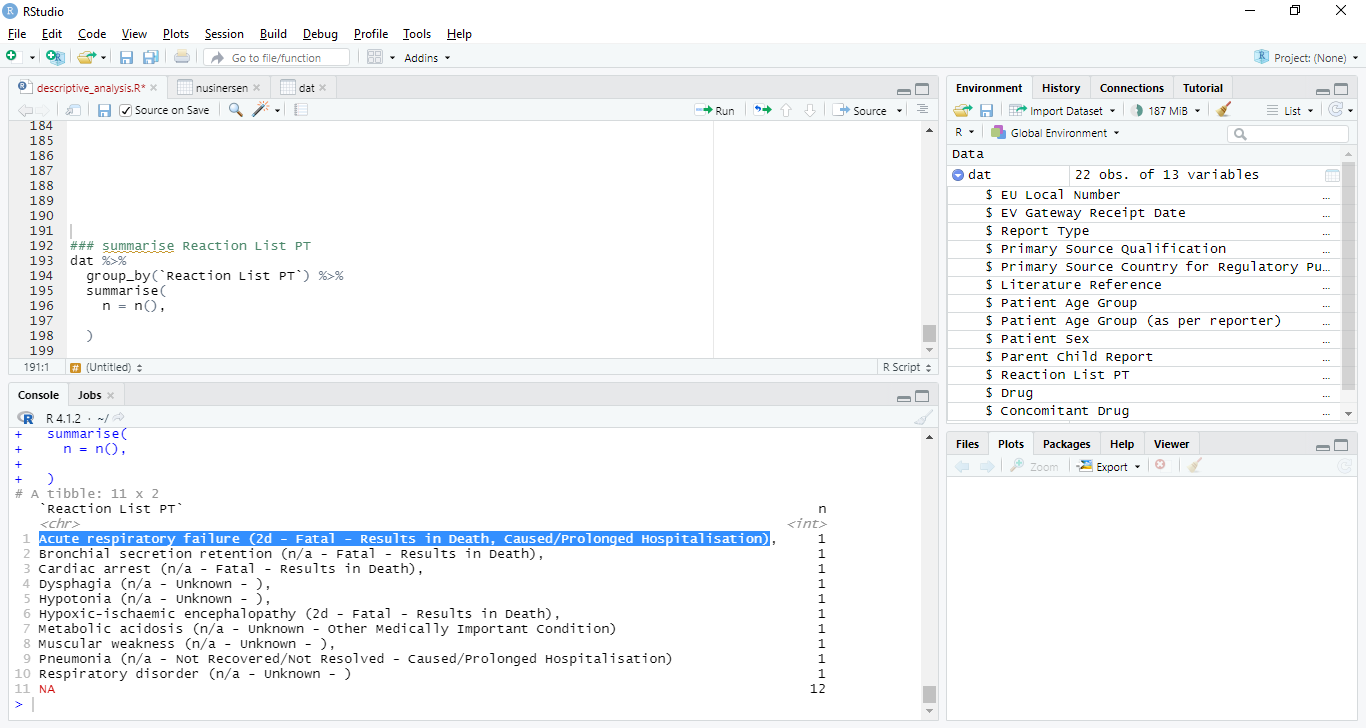
dat creates a character vector of the strings to be split; for this question that's really all that's needed for a reprex.
Examination of dat shows a consistent pattern of separation into a forepart before the first curved bracket ( and an aftpart from the first curved bracket until the end of the string.
Two regular expressions are composed to distinguish the two parts. The first specifies the beginning ^ of the string followed by anything .* followed by (, which is a special character which must be escaped with \\(. The second specifies a blank followed by ( and then anything .* to the end $ of the character.
The second search patterns leaves some leftover characters, either ) or - that the third and fourth expressions address.
main creates a character vector of the forepart and a separate vector of the aftpart, in three steps—the portion leftover after forepart is removed which is then piped |> to remove the trailing ) and piped again to remove the trailing -.
your code works fine, but it would be better if the code drew directly from the column "Reaction_List_PT" and I didn't enter the various strings, e.g.
"Acute respiratory failure (2d - Fatal - Results in Death, Caused/Prolonged Hospitalisation)",
"Bronchial secretion retention (n/a - Fatal - Results in Death)",
"Cardiac arrest (n/a - Fatal - Results in Death)" and so on.
I don't understand what you mean, the code works on Reaction_List_PT directly. If you are referring to the sample data, I already clarified in the code comments that you need to use your own data frame instead, that sample data in copy/paste friendly format is just for reproducibility purposes.
Screenshots are considered a bad practice here since we cant select and copy code from them, post formated code instead. Here is how to do it
I can't be sure this code is going to work for you since you are not providing a reproducible example and I'm not willing to download a file from that source.
library(tidyverse)
dat %>%
group_by(`Reaction List PT`) %>%
summarise(n = n()) %>%
mutate(`Reaction List PT` = str_replace(`Reaction List PT`, "\\(", "- "),
`Reaction List PT` = str_remove(`Reaction List PT`, "\\),")) %>%
separate(`Reaction List PT`,
into = c("Reaction_List_PT", "Duration",
"Outcome", "Seriousness_criteria"),
sep = " - ")
Since you are a newbie I strongly encourage you to learn how to ask your questions providing a proper REPRoducible EXample (reprex) illustrating your issue. This is not only the most effective way to ask for help it is also the most polite.
I always limit my answers to the data provided. For that purpose data is what can be cut and pasted, in this case a vector. A column is just a vector encased in a data frame. Depending on the workflow design, it can either be used extracted as a vector for separate treatment or handled in place. The syntax for the latter differs. For the question as posed with the data provided, that is a meta-issue.