Hello again,
Pardon long reply. Thank you for that "should have been" result @cderv and advice on what you need as helper @pgensler !!!!
I hope to be able to produce easy and nice to read reprex @nick with all the help I have been receiving from everyone and @mara! I played around with the different suggestions and hope they are right even thought my original question has been answered.
reprex::reprex_info()
#> Warning in as.POSIXlt.POSIXct(Sys.time()): unknown timezone 'default/
#> Europe/Paris'
#> Created by the reprex package v0.1.1.9000 on 2017-11-26
library (tidyverse)
#> Loading tidyverse: ggplot2
#> Loading tidyverse: tibble
#> Loading tidyverse: tidyr
#> Loading tidyverse: readr
#> Loading tidyverse: purrr
#> Loading tidyverse: dplyr
#> Warning: package 'dplyr' was built under R version 3.4.2
#> Conflicts with tidy packages ----------------------------------------------
#> filter(): dplyr, stats
#> lag(): dplyr, stats
library(knitr)
library(kableExtra)
data.frame(tribble(
~type, ~year,
"Very Satisfied", 1982L,
NA, 2012L,
"Very Satisfied", 1982L,
"Very Satisfied", 1982L,
"Very Satisfied", 1982L,
"Very Satisfied", 2012L,
"Other", 2012L,
"Other", 2012L,
"Other", 1982L,
NA, 1982L,
"Very Satisfied", 2012L,
NA, 2012L,
"Very Satisfied", 1982L,
NA, 1982L,
"Very Satisfied", 1982L,
NA, 1982L,
"Other", 2012L,
"Very Satisfied", 2012L,
NA, 1982L,
"Other", 2012L,
"Very Satisfied", 2012L,
"Very Satisfied", 1982L,
"Very Satisfied", 1982L,
"Very Satisfied", 2012L,
"Very Satisfied", 2012L,
"Very Satisfied", 2012L,
"Other", 2012L,
"Other", 1982L,
NA, 2012L,
"Very Satisfied", 2012L,
NA, 1982L,
NA, 2012L,
"Very Satisfied", 2012L,
"Other", 1982L,
"Other", 1982L,
NA, 1982L,
"Other", 1982L,
"Other", 2012L,
"Very Satisfied", 1982L,
"Very Satisfied", 2012L,
"Very Satisfied", 2012L,
"Very Satisfied", 2012L,
"Other", 2012L,
"Very Satisfied", 2012L,
NA, 2012L,
"Other", 1982L,
"Very Satisfied", 2012L,
"Very Satisfied", 1982L,
"Other", 2012L,
"Other", 1982L
)) %>%
count(year, type) %>%
group_by(year) %>%
mutate(prop = n / sum(n)) %>%
select(-n) %>%
spread(key = type, value = prop) %>%
arrange(desc(year)) %>%
kable("html") %>%
kable_styling()
|
year
|
Other
|
Very Satisfied
|
<NA>
|
|
2012
|
0.2962963
|
0.5185185
|
0.1851852
|
|
1982
|
0.3043478
|
0.4347826
|
0.2608696
|
```
reprex::reprex_info()
#> Warning in as.POSIXlt.POSIXct(Sys.time()): unknown timezone 'default/
#> Europe/Paris'
#> Created by the reprex package v0.1.1.9000 on 2017-11-26
library (tidyverse)
#> Loading tidyverse: ggplot2
#> Loading tidyverse: tibble
#> Loading tidyverse: tidyr
#> Loading tidyverse: readr
#> Loading tidyverse: purrr
#> Loading tidyverse: dplyr
#> Warning: package 'dplyr' was built under R version 3.4.2
#> Conflicts with tidy packages ----------------------------------------------
#> filter(): dplyr, stats
#> lag(): dplyr, stats
library(knitr)
library(kableExtra)
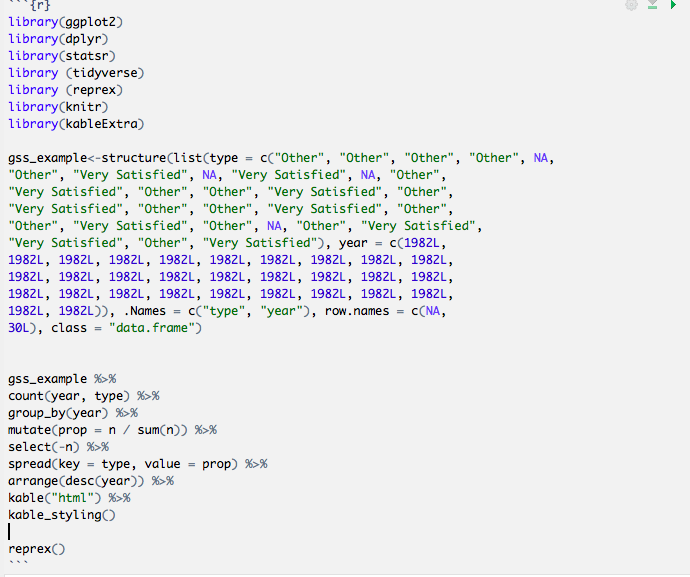
gss_example<-structure(list(type = c("Very Satisfied", NA, "Very Satisfied",
"Very Satisfied", "Very Satisfied", "Very Satisfied", "Other",
"Other", "Other", NA, "Very Satisfied", NA, "Very Satisfied",
NA, "Very Satisfied", NA, "Other", "Very Satisfied", NA, "Other",
"Very Satisfied", "Very Satisfied", "Very Satisfied", "Very Satisfied",
"Very Satisfied", "Very Satisfied", "Other", "Other", NA, "Very Satisfied",
NA, NA, "Very Satisfied", "Other", "Other", NA, "Other", "Other",
"Very Satisfied", "Very Satisfied", "Very Satisfied", "Very Satisfied",
"Other", "Very Satisfied", NA, "Other", "Very Satisfied", "Very Satisfied",
"Other", "Other"), year = c(1982L, 2012L, 1982L, 1982L, 1982L,
2012L, 2012L, 2012L, 1982L, 1982L, 2012L, 2012L, 1982L, 1982L,
1982L, 1982L, 2012L, 2012L, 1982L, 2012L, 2012L, 1982L, 1982L,
2012L, 2012L, 2012L, 2012L, 1982L, 2012L, 2012L, 1982L, 2012L,
2012L, 1982L, 1982L, 1982L, 1982L, 2012L, 1982L, 2012L, 2012L,
2012L, 2012L, 2012L, 2012L, 1982L, 2012L, 1982L, 2012L, 1982L
)), .Names = c("type", "year"), row.names = c(NA, 50L), class = "data.frame")
gss_example %>%
count(year, type) %>%
group_by(year) %>%
mutate(prop = n / sum(n)) %>%
select(-n) %>%
spread(key = type, value = prop) %>%
arrange(desc(year)) %>%
kable("html") %>%
kable_styling()
|
year
|
Other
|
Very Satisfied
|
<NA>
|
|
2012
|
0.2962963
|
0.5185185
|
0.1851852
|
|
1982
|
0.3043478
|
0.4347826
|
0.2608696
|
```
reprex::reprex_info()
#> Warning in as.POSIXlt.POSIXct(Sys.time()): unknown timezone 'default/
#> Europe/Paris'
#> Created by the reprex package v0.1.1.9000 on 2017-11-26
library (tidyverse)
#> Loading tidyverse: ggplot2
#> Loading tidyverse: tibble
#> Loading tidyverse: tidyr
#> Loading tidyverse: readr
#> Loading tidyverse: purrr
#> Loading tidyverse: dplyr
#> Warning: package 'dplyr' was built under R version 3.4.2
#> Conflicts with tidy packages ----------------------------------------------
#> filter(): dplyr, stats
#> lag(): dplyr, stats
library(knitr)
library(kableExtra)
data.frame(stringsAsFactors=FALSE,
type = c("Very Satisfied", NA, "Very Satisfied", "Very Satisfied",
"Very Satisfied", "Very Satisfied"),
year = c(1982L, 2012L, 1982L, 1982L, 1982L, 2012L)) %>%
count(year, type) %>%
group_by(year) %>%
mutate(prop = n / sum(n)) %>%
select(-n) %>%
spread(key = type, value = prop) %>%
arrange(desc(year)) %>%
kable("html") %>%
kable_styling()
|
year
|
Very Satisfied
|
<NA>
|
|
2012
|
0.5
|
0.5
|
|
1982
|
1.0
|
NA
|
```


 you need for the example. You see I only load a few and it works.
you need for the example. You see I only load a few and it works.