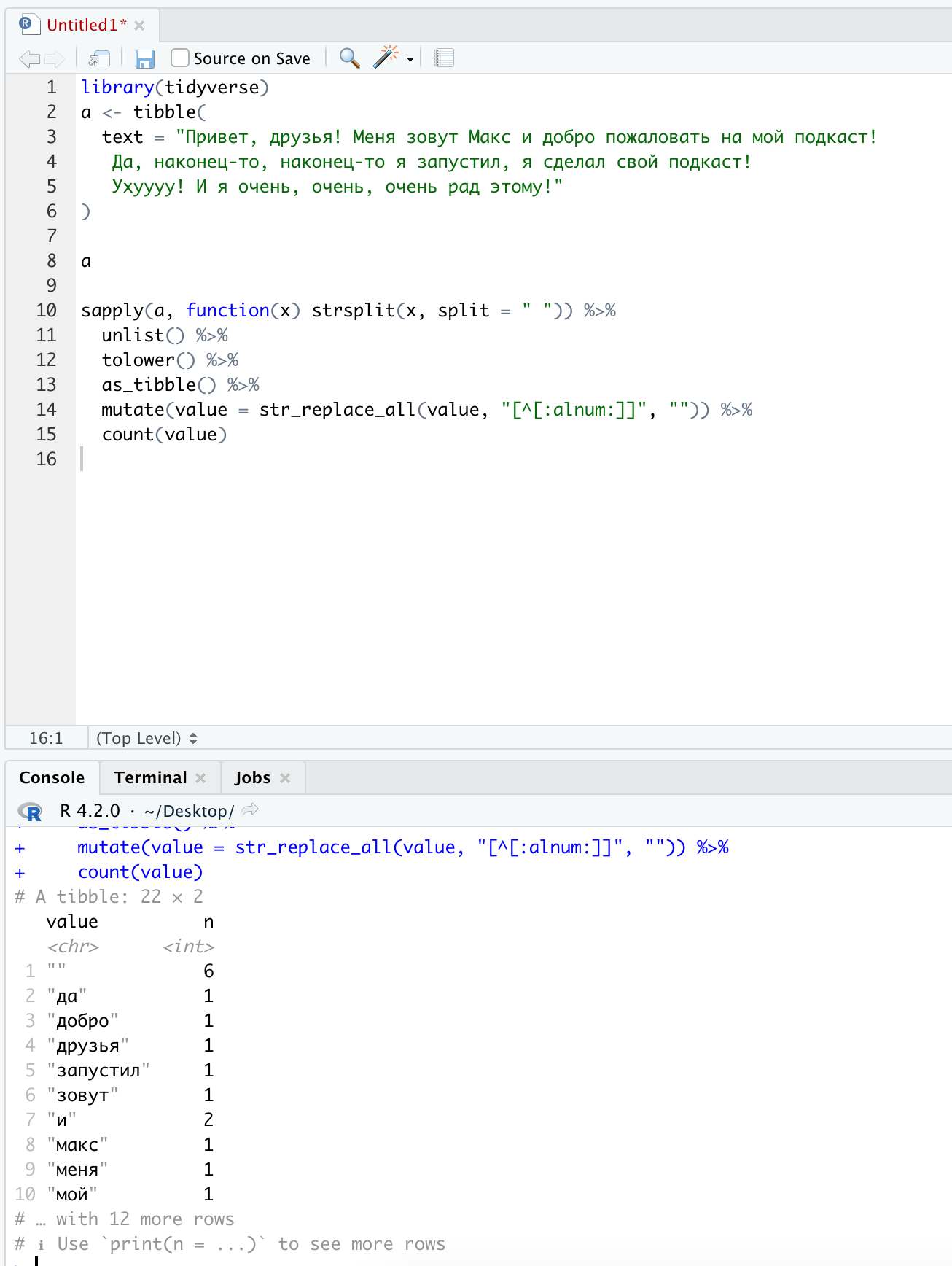
Mmm quite strange, because if I run the same code this is the result:
library(tidyverse)
a <- tibble(
text = "Привет, друзья! Меня зовут Макс и добро пожаловать на мой подкаст!
Да, наконец-то, наконец-то я запустил, я сделал свой подкаст!
Ухуууу! И я очень, очень, очень рад этому!"
)
a
sapply(a, function(x) strsplit(x, split = " ")) %>%
unlist() %>%
tolower() %>%
as_tibble() %>%
mutate(value = str_replace_all(value, "[^[:alnum:]]", "")) %>%
count(value)