Probably an Amazon self-protective measure to guard against bots. Their own API has a rate throttle of 10/second, so they aren’t eager to be scrapped. One way for them to know is to look at the browser header of the HTTP request. I ran into this with the sec.gov site.
Do a test of getting a page on some other site. If it works then Amazon defense mechanisms are likely the problem, and evading those strays too close to the red line where acceptable use becomes hacking.
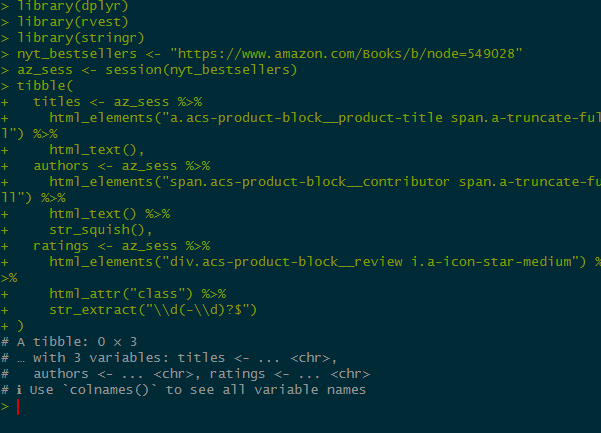
library(dplyr)
library(rvest)
library(stringr)
nyt_bestsellers <- "https://www.amazon.com/Books/b/node=549028"
az_sess <- session(nyt_bestsellers)
tibble(
titles <- az_sess %>%
html_elements("a.acs-product-block__product-title span.a-truncate-full") %>%
html_text(),
authors <- az_sess %>%
html_elements("span.acs-product-block__contributor span.a-truncate-full") %>%
html_text() %>%
str_squish(),
ratings <- az_sess %>%
html_elements("div.acs-product-block__review i.a-icon-star-medium") %>%
html_attr("class") %>%
str_extract("\\d(-\\d)?$")
)
#> # A tibble: 140 × 3
#> `titles <- ...` autho…¹ ratin…²
#> <chr> <chr> <chr>
#> 1 Lessons in Chemistry: A Novel Bonnie… 4-5
#> 2 The House in the Pines: A Novel Ana Re… 3-5
#> 3 Without a Trace: A Novel Daniel… 4-5
#> 4 The Boys from Biloxi: A Legal Thriller John G… 4-5
#> 5 Demon Copperhead: A Novel Barbar… 4-5
#> 6 Fairy Tale Stephe… 4-5
#> 7 Tomorrow, and Tomorrow, and Tomorrow: A novel Gabrie… 4-5
#> 8 Mad Honey: A Novel Jodi P… 4-5
#> 9 The Midnight Library: A Novel Matt H… 4-5
#> 10 Babel: Or the Necessity of Violence: An Arcane History of th… R. F K… 4-5
#> # … with 130 more rows, and abbreviated variable names ¹`authors <- ...`,
#> # ²`ratings <- ...`
Created on 2023-01-18 by the reprex package (v2.0.1)
I’m speculating that the reason you and I get an empty tibble is that neither of us have a token and @M_AcostaCH does. But about that I could be wrong.