Hello
Can you help me please.
When downloading the file to excel I get data that should be numeric in text format.
How could I modify the code in Rstudio?
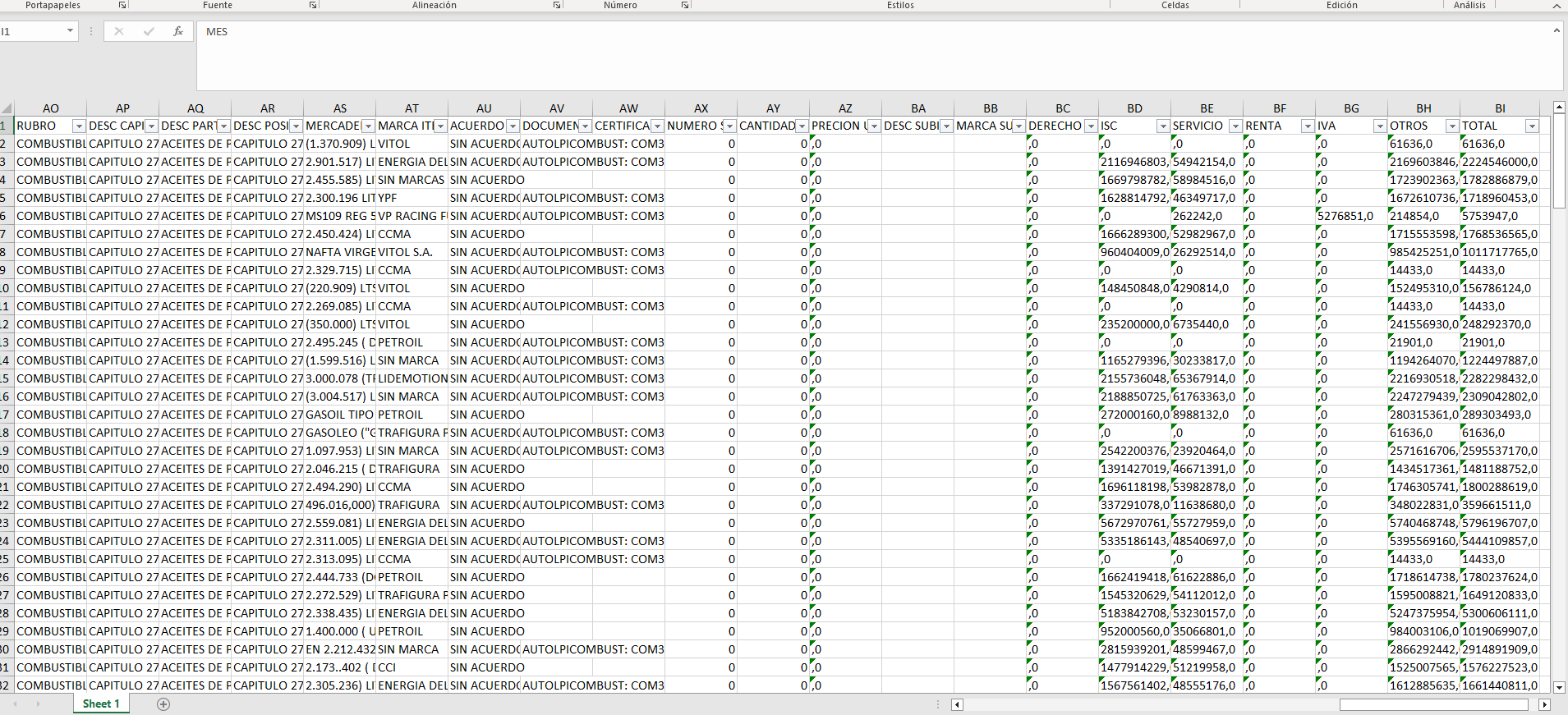
Can you post values of TOTAL that don't convert? (Also, better to copy and paste than to post pictures. They're hard to read.)
library(tidyverse)
library(readr)
library(openxlsx)
library(dplyr)
##2022
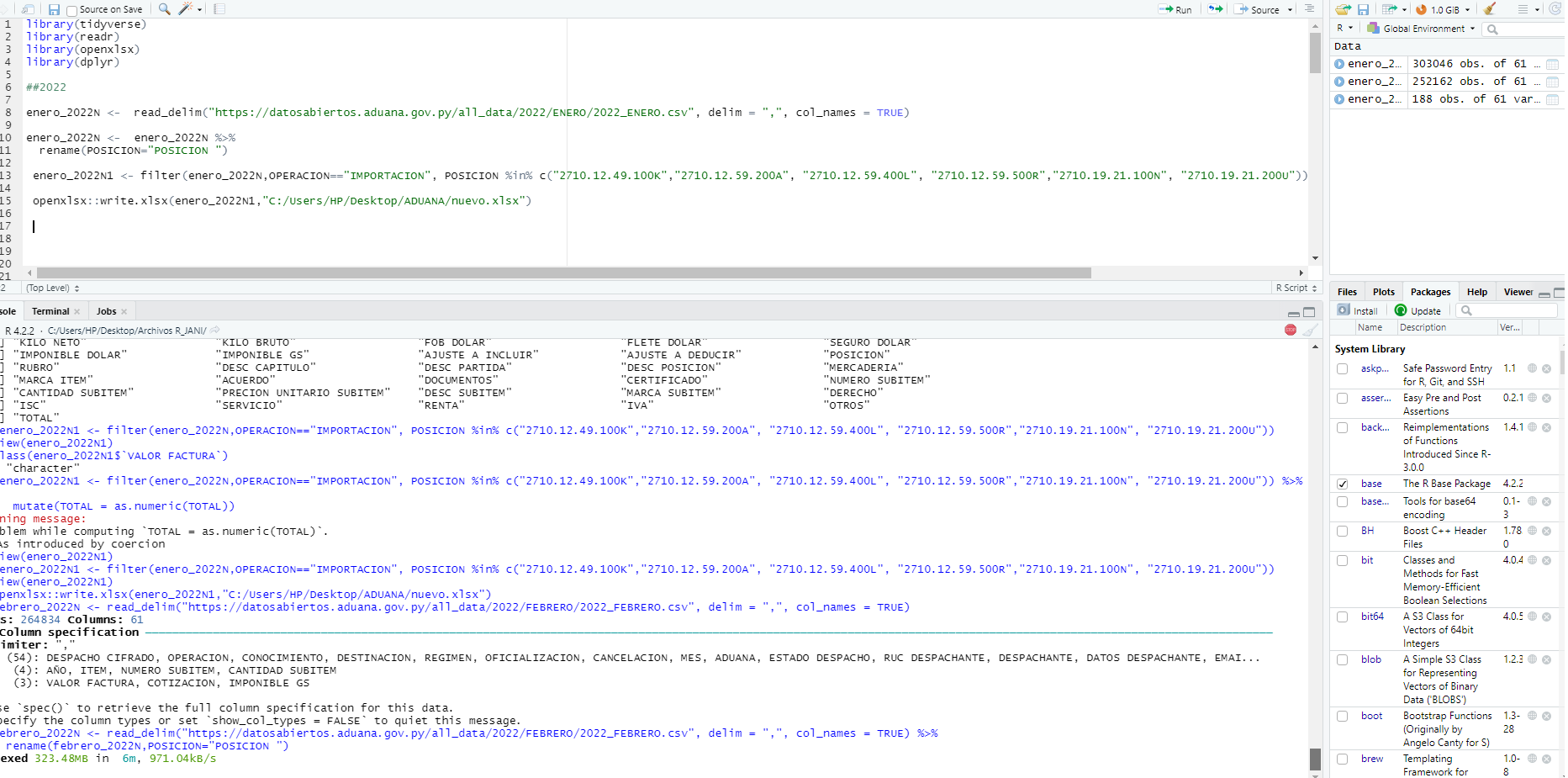
enero_2022N <- read_delim("https://datosabiertos.aduana.gov.py/all_data/2022/ENERO/2022_ENERO.csv", delim = ",", col_names = TRUE)
enero_2022N <- enero_2022N %>%
rename(POSICION="POSICION ")
enero_2022N1 <- filter(enero_2022N,OPERACION=="IMPORTACION", POSICION %in% c("2710.12.49.100K","2710.12.59.200A", "2710.12.59.400L", "2710.12.59.500R","2710.19.21.100N", "2710.19.21.200U"))
openxlsx::write.xlsx(enero_2022N1,"C:/Users/HP/Desktop/ADUANA/nuevo.xlsx")
I wasn't able to read the data (don't know why). Could you just post the variable giving you trouble, which I think is TOTAL.
the database is very heavy, it takes a few minutes to load.
When downloading the file is the problem, when I open the excel. There are data such as the TOTAL variable, SERVICE, ISC and others, they appear in text format when they should be numbers.
Hi, when you load in R, you could try with this for change to character to numeric.
enero_2022N$TOTAL -> as.numeric(enero_2022N$TOTAL) # the same way for the other columns.
@Gissella, we can't see what you don't show us. Try doing dput(enero_2022N$TOTAL) and then copy and paste the rsults here. If that variable is very long, you can do dput(head(enero_2022N$TOTAL,50))
Thank you very much, I tried with that code but when transforming
from CHARTER to "numeric" in the TOTAL column NA values appear
This appears to me:
dput(head(enero_2022N$TOTAL,50))
c("5785635,0", "11336310,0", "5590671,0", "4876949,0", "5408942,0",
"5145199,0", "45487970,0", "4635773,0", "621925,0", "621925,0",
"11608003,0", "4807981,0", "3865585,0", "2274601,0", "6623293,0",
"27799147,0", "20799358,0", "6495108,0", "5576869,0", "4226413,0",
"7308357,0", "6237362,0", "4635773,0", "6233134,0", "38359982,0",
"30519301,0", "5292691,0", "786263,0", "5219845,0", "9367186,0",
"5754838,0", "3892784,0", "5696274,0", "6513276,0", "11395046,0",
"6078434,0", "15014137,0", "7465951,0", "1109675,0", "1109675,0",
"16925957,0", "9632171,0", "7223388,0", "5327698,0", "4802363,0",
"944305,0", "6064423,0", "3038906,0", "1662544,0", "5678437,0"
)
I think you have to replace the comma that is used as the decimal mark with a period.
TOTAL <- c("5785635,0", "11336310,0", "5590671,0", "4876949,0", "5408942,0",
"5145199,0", "45487970,0", "4635773,0", "621925,0", "621925,0",
"11608003,0", "4807981,0", "3865585,0", "2274601,0", "6623293,0",
"27799147,0", "20799358,0", "6495108,0", "5576869,0", "4226413,0",
"7308357,0", "6237362,0", "4635773,0", "6233134,0", "38359982,0",
"30519301,0", "5292691,0", "786263,0", "5219845,0", "9367186,0",
"5754838,0", "3892784,0", "5696274,0", "6513276,0", "11395046,0",
"6078434,0", "15014137,0", "7465951,0", "1109675,0", "1109675,0",
"16925957,0", "9632171,0", "7223388,0", "5327698,0", "4802363,0",
"944305,0", "6064423,0", "3038906,0", "1662544,0", "5678437,0"
)
class(TOTAL)
#> [1] "character"
TOTAL <- as.numeric(sub(",","\\.", TOTAL))
class(TOTAL)
#> [1] "numeric"
Created on 2023-02-25 with reprex v2.0.2
#For your data frame, try this
enero_2022N$TOTAL <- as.numeric(sub(",","\\.", enero_2022N$TOTAL))
I deeply suspect that @FJCC is right. In the U.S. we use a decimal point where in Europe a comma is used. You may be able to get around this by adding dec="," to your read.delim function.
I have managed download the file with {data.table} which deals with the decimal problem.
@ Gissella was not joking, it is a good sized file ( 252162 X 61)
library(data.table)
dat1 <- fread("https://datosabiertos.aduana.gov.py/all_data/2022/ENERO/2022_ENERO.csv", dec = ',')
We also have a names() problem.
dat1[, .(names(dat1))]
V1
1: DESPACHO CIFRADO
2: OPERACION
3: CONOCIMIENTO
4: DESTINACION
5: REGIMEN
6: OFICIALIZACION
7: CANCELACION
8: AÑO
9: MES
10: ADUANA
11: ESTADO DESPACHO
12: RUC DESPACHANTE
13: DESPACHANTE
14: DATOS DESPACHANTE
15: EMAIL DESPACHANTE
16: RUC IMPORTADOR/EXPORTADOR
17: IMPORTADOR
18: EMAIL IMPORTADOR/EXPORTADOR
19: FACTURA
20: VALOR FACTURA
21: COTIZACION
22: MEDIO TRANSPORTE
23: PROVEEDOR
24: CANAL
25: ITEM
26: PAIS ORIGEN
27: PAIS PROCEDENCIA/DESTINO
28: USO
29: UNIDAD MEDIDA ESTADISTICA
30: CANTIDAD ESTADISTICA
31: KILO NETO
32: KILO BRUTO
33: FOB DOLAR
34: FLETE DOLAR
35: SEGURO DOLAR
36: IMPONIBLE DOLAR
37: IMPONIBLE GS
38: AJUSTE A INCLUIR
39: AJUSTE A DEDUCIR
40: POSICION
41: RUBRO
42: DESC CAPITULO
43: DESC PARTIDA
44: DESC POSICION
45: MERCADERIA
46: MARCA ITEM
47: ACUERDO
48: DOCUMENTOS
49: CERTIFICADO
50: NUMERO SUBITEM
51: CANTIDAD SUBITEM
52: PRECION UNITARIO SUBITEM
53: DESC SUBITEM
54: MARCA SUBITEM
55: DERECHO
56: ISC
57: SERVICIO
58: RENTA
59: IVA
60: OTROS
61: TOTAL
V1
Duh, it occurs to me that something like this is really all that is needed.
mynames <- dat1[, names(dat1)]
new_names <- gsub(" ", "_", mynames)
names(dat1) <- new_names
setnames(dat, "POSICION_", "POSICION") # tidying up that one name
Thank you very much everyone for the help. ![]()
This answer helped me visualize variables that corresponded to numeric format.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.