Thank you for all the support. Sorry was not being clear. But i did provided all the explanations.
Yes, but they are not clear enough, have in mind that not everybody here is a native English speaker so you have to keep things simple concise and clear if you want to improve your chances of getting help.
I have made a last attempt, is this what you mean?
library(tidyverse)
library(lubridate)
data$Date_Created = ymd(data$Date_Created)
data %>%
mutate(earliest_date = Date_Created %m-% months(6),
sum_nos = pmap_dbl(.l = list(earliest_date,
Date_Created,
location),
~ data %>%
filter(location == ..3,Date_Created >= ..1 & Date_Created <= ..2) %>%
summarise(sum_nos = sum(nos)) %>%
.$sum_nos
))
#> Id nos grade Date_Created location earliest_date sum_nos
#> 1 1 4 3 2016-03-01 Aus 2015-09-01 4
#> 2 2 2 3 2016-03-15 Aus 2015-09-15 6
#> 3 3 3 3 2016-03-21 Aus 2015-09-21 9
#> 4 4 2 3 2016-05-25 Ind 2015-11-25 2
#> 5 5 3 3 2016-07-29 Ind 2016-01-29 7
#> 6 6 2 2 2016-07-29 Ind 2016-01-29 7
#> 7 7 2 2 2016-07-29 ML 2016-01-29 2
#> 8 8 3 4 2016-08-04 ML 2016-02-04 5
#> 9 9 1 4 2016-10-14 Aus 2016-04-14 1
#> 10 10 5 3 2016-10-31 Ind 2016-04-30 12
#> 11 11 2 3 2017-04-13 Ind 2016-10-13 7
#> 12 12 1 4 2017-04-13 PA 2016-10-13 1
#> 13 13 2 3 2017-04-13 KA 2016-10-13 2
#> 14 14 1 3 2017-04-13 LA 2016-10-13 1
#> 15 15 1 4 2017-06-29 LA 2016-12-29 2
1 Like
Thank you so much . Perfect this is what i was looking for. Sorry i can completely understand your point thats why i try to give example. Will be more clear in future.
-
But When i run your code i am getting all the values as same. is that something wrong with the R or my code? Please guide.
-
Also if i would like to another filter variable called Grade. it will be same as like below
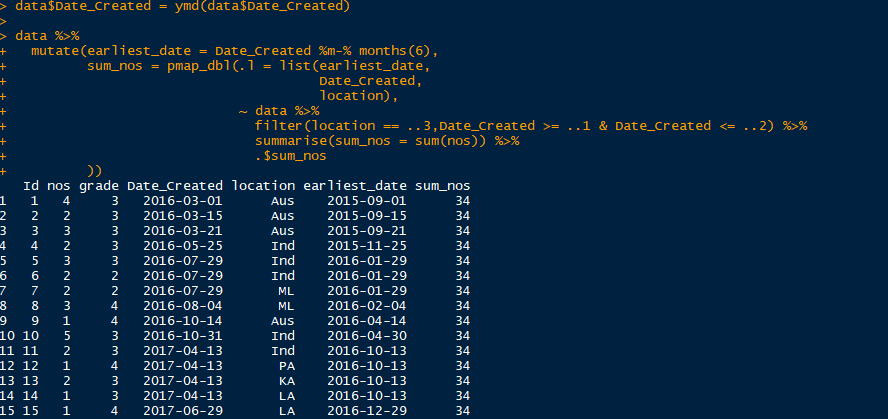
data %>%
mutate(earliest_date = Date_Created %m-% months(6),
sum_nos = pmap_dbl(.l = list(earliest_date,
Date_Created,
location,
grade),
~ data %>%
filter(grade==..4,location == ..3,Date_Created >= ..1 & Date_Created <= ..2) %>%
summarise(sum_nos = sum(nos)) %>%
.$sum_nos
))
Have you tried on a clean R session?, maybe is a name conflic with other objects you have loaded in memory.
Yes
- Cleared the R session and restarted it but still getting the same result. not sure why.
- Also one more help suppose i want to create one more variable "count" which satisfies the above conditions. so the code will be like this?
sai %>%
mutate(earliest_date = Date_Created %m-% months(6),
sum_nos = pmap_dbl(.l = list(earliest_date,
Date_Created,
location),
~ data %>%
filter(location == ..3,Date_Created >= ..1 & Date_Created <= ..2) %>%
Count=n()) %>%
.$sum_nos
))
The below for loops works and creates count variable. but was wondering if the vectorize form is the same as above.
library(lubridate)
data$Date_Created <- as.Date(data$Date_Created, "%m/%d/%Y") # convert to date
data$less6month <- data$Date_Created %m-% months(6) # subtract 6 months
data$count <- 0 # initialise counter
i <- 1 # for testing
for (i in 1:nrow(data)){ # loop through rows
compare all rows to row i
compare <- (datanew1$location==datanew1$location[i]) &
(data$grade==data$grade[i]) &
(data$Date_Created >=data$less6month[i])&
(data$Date_Created <= data$Date_Created[i])
count number of TRUE results (subtract 1 for row i)
data$count[i] <- sum(compare)
}
I can't help you with this without a proper reproducible example, please read this link and try to make one.
This is wrong syntax, if you want to learn how to use this functions then read this free ebook
1 Like
Please find below the data and the reprex. The output still remains the same
sai <- data.frame(
Id = c(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L,
14L, 15L),
nos = c(4L, 2L, 3L, 2L, 3L, 2L, 2L, 3L, 1L, 5L, 2L, 1L, 2L, 1L, 1L),
grade = c(3L, 3L, 3L, 3L, 3L, 2L, 2L, 4L, 4L, 3L, 3L, 4L, 3L, 3L, 4L),
Date_Created = c("2016-03-01", "2016-03-15", "2016-03-21", "2016-05-25",
"2016-07-29", "2016-07-29", "2016-07-29", "2016-08-04",
"2016-10-14", "2016-10-31", "2017-04-13", "2017-04-13",
"2017-04-13", "2017-04-13", "2017-06-29"),
location = as.factor(c("Aus", "Aus", "Aus", "Ind", "Ind", "Ind", "ML",
"ML", "Aus", "Ind", "Ind", "PA", "KA", "LA",
"LA"))
)
library(tidyverse)
library(lubridate)
sai$Date_Created = ymd(sai$Date_Created)
sai %>%
mutate(earliest_date = Date_Created %m-% months(6),
sum_nos = map2_dbl(.x = earliest_date,
.y = Date_Created,
~ sai %>%
filter(Date_Created >= .x & Date_Created <= .y) %>%
summarise(sum_nos = sum(nos)) %>%
.$sum_nos
))
Thank you for the book. Sure will read it.
That works normally for me, what happens if you run this code through the reprex package?
reprex::reprex({
sai <- data.frame(
Id = c(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L,
14L, 15L),
nos = c(4L, 2L, 3L, 2L, 3L, 2L, 2L, 3L, 1L, 5L, 2L, 1L, 2L, 1L, 1L),
grade = c(3L, 3L, 3L, 3L, 3L, 2L, 2L, 4L, 4L, 3L, 3L, 4L, 3L, 3L, 4L),
Date_Created = c("2016-03-01", "2016-03-15", "2016-03-21", "2016-05-25",
"2016-07-29", "2016-07-29", "2016-07-29", "2016-08-04",
"2016-10-14", "2016-10-31", "2017-04-13", "2017-04-13",
"2017-04-13", "2017-04-13", "2017-06-29"),
location = as.factor(c("Aus", "Aus", "Aus", "Ind", "Ind", "Ind", "ML",
"ML", "Aus", "Ind", "Ind", "PA", "KA", "LA",
"LA"))
)
library(tidyverse)
library(lubridate)
sai$Date_Created = ymd(sai$Date_Created)
sai %>%
mutate(earliest_date = Date_Created %m-% months(6),
sum_nos = map2_dbl(.x = earliest_date,
.y = Date_Created,
~ sai %>%
filter(Date_Created >= .x & Date_Created <= .y) %>%
summarise(sum_nos = sum(nos)) %>%
.$sum_nos
))
})
Its gives the below error if i run with reprex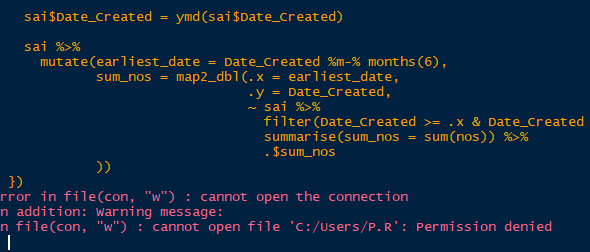
[quote="srini, post:47, topic:33553"]
Need one more help how can i transform this for loop into the vectorize form
ibrary(lubridate)
data$Date_Created <- as.Date(data$Date_Created, "%m/%d/%Y") # convert to date
data$less6month <- data$Date_Created %m-% months(6) # subtract 6 months
data$count <- 0 # initialise counter
i <- 1 # for testing
for (i in 1:nrow(data)){ # loop through rows
compare all rows to row i
compare <- (datanew1$location==datanew1$location[i]) &
(data$grade==data$grade[i]) &
(data$Date_Created >=data$less6month[i])&
(data$Date_Created <= data$Date_Created[i])
count number of TRUE results (subtract 1 for row i)
data$count[i] <- sum(compare)
}
I'm going to give you the solution, but I want to ask you for something in return, please read and follow this guides before writing your next post/topic
library(tidyverse)
library(lubridate)
data <- data.frame(
Id = c(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L,
14L, 15L),
nos = c(4L, 2L, 3L, 2L, 3L, 2L, 2L, 3L, 1L, 5L, 2L, 1L, 2L, 1L, 1L),
grade = c(3L, 3L, 3L, 3L, 3L, 2L, 2L, 4L, 4L, 3L, 3L, 4L, 3L, 3L, 4L),
Date_Created = c("2016-03-01", "2016-03-15", "2016-03-21", "2016-05-25",
"2016-07-29", "2016-07-29", "2016-07-29", "2016-08-04",
"2016-10-14", "2016-10-31", "2017-04-13", "2017-04-13",
"2017-04-13", "2017-04-13", "2017-06-29"),
location = as.factor(c("Aus", "Aus", "Aus", "Ind", "Ind", "Ind", "ML",
"ML", "Aus", "Ind", "Ind", "PA", "KA", "LA",
"LA"))
)
data$Date_Created = ymd(data$Date_Created)
data %>%
mutate(earliest_date = Date_Created %m-% months(6),
count = pmap_dbl(.l = list(location,
grade,
earliest_date,
Date_Created),
~ data %>%
filter(location == ..1, grade == ..2, Date_Created >= ..3 & Date_Created <= ..4) %>%
summarise(count = n()) %>%
.$count
),
sum_nos = pmap_dbl(.l = list(location,
grade,
earliest_date,
Date_Created),
~ data %>%
filter(location == ..1, grade == ..2, Date_Created >= ..3 & Date_Created <= ..4) %>%
summarise(sum_nos = sum(nos)) %>%
.$sum_nos
)
)
#> Id nos grade Date_Created location earliest_date count sum_nos
#> 1 1 4 3 2016-03-01 Aus 2015-09-01 1 4
#> 2 2 2 3 2016-03-15 Aus 2015-09-15 2 6
#> 3 3 3 3 2016-03-21 Aus 2015-09-21 3 9
#> 4 4 2 3 2016-05-25 Ind 2015-11-25 1 2
#> 5 5 3 3 2016-07-29 Ind 2016-01-29 2 5
#> 6 6 2 2 2016-07-29 Ind 2016-01-29 1 2
#> 7 7 2 2 2016-07-29 ML 2016-01-29 1 2
#> 8 8 3 4 2016-08-04 ML 2016-02-04 1 3
#> 9 9 1 4 2016-10-14 Aus 2016-04-14 1 1
#> 10 10 5 3 2016-10-31 Ind 2016-04-30 3 10
#> 11 11 2 3 2017-04-13 Ind 2016-10-13 2 7
#> 12 12 1 4 2017-04-13 PA 2016-10-13 1 1
#> 13 13 2 3 2017-04-13 KA 2016-10-13 1 2
#> 14 14 1 3 2017-04-13 LA 2016-10-13 1 1
#> 15 15 1 4 2017-06-29 LA 2016-12-29 1 1
2 Likes
Thank you so much for all the help. This is perfect what i was looking for. Kudos ![]() I make sure that next time i post i will follow the guidelines.
I make sure that next time i post i will follow the guidelines.![]()
1 Like
One more help if you can suggest the resources in R to improve my coding skills. Thank you
These are my favorite books for getting anybody up and running with R (and they are free)
I also recommend this online course
1 Like
Thank you so much.!!
Thank you for the solution. This was the exactly what i was working through. I replicated the exact code and the data. Unfortunately the code is not giving the exact result you posted. I cleared the R session and ran again.
That is just telling you that another package has a function with the same name, so if you want to use for example the plyr version of arrange() then you would have to specify the source like this plyr::arrange()
ok. Thank you. But still not sure why the code is not executing. There are two problems.
If the code executes it gives two problems
- The output has the same values across all the rows.
- The code is not running.