Hello I have a problem about 'pivot_wider' in R. I have a transaction-level dataset of three columns: unique ID, customers, and purchase time. The example is shown below.
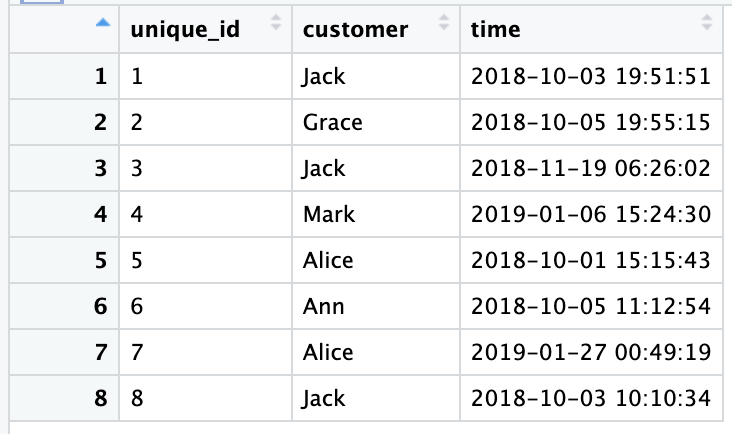
The first column, unique_ID is distinctive for each row. The second column is the customer and some customers only purchased only, like Grace or Mark while some other customers repurchased, like Jack and Alice. I want to widen this table in the following way since I need to calculate the number of days between the orders if they repurchased but I also need to keep the unique ID for each customer since I need to join other tables later. For Jack, he has two different unique_id and how can I keep these two different unique_id for him? Thanks for your help.

customer <- c('Jack', 'Grace', 'Jack','Mark', 'Alice', 'Ann', 'Alice', 'Jack')
unique_id <- 1:8
time <- c("2018-10-03 19:51:51",
"2018-10-05 19:55:15",
"2018-11-19 06:26:02",
"2019-01-06 15:24:30",
"2018-10-01 15:15:43",
"2018-10-05 11:12:54",
"2019-01-27 00:49:19",
"2018-10-03 10:10:34")
data <- as.data.frame(cbind(unique_id, customer, time))
test <- data %>%
group_by(customer) %>%
arrange(time) %>% # unnecessary if sorted already
mutate(instance = row_number()) %>%
ungroup() %>%
pivot_wider(id_cols = c(unique_id, customer), names_from = instance, values_from = time) %>%
mutate(whether_to_repurchase = 1* !is.na('2')) # 0 if 2 NA; 1 if not
There is the output.
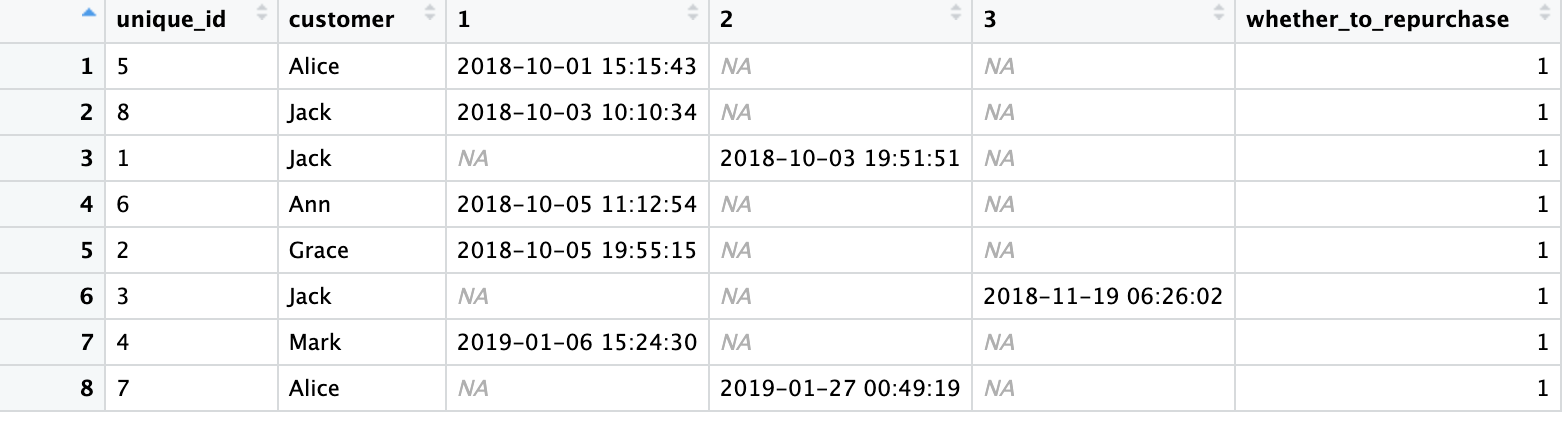
Then how can I know whether the customer repurchase or not in the future? The column 'whether to repurchase' is always 1. Thanks for your help.