Hello, I have a question about pivot_wider. After applying for it, it doesn't change the dimensions of the original dataset.
I have a large dataset about the order data and some customers repurchased it while some didn't do it.
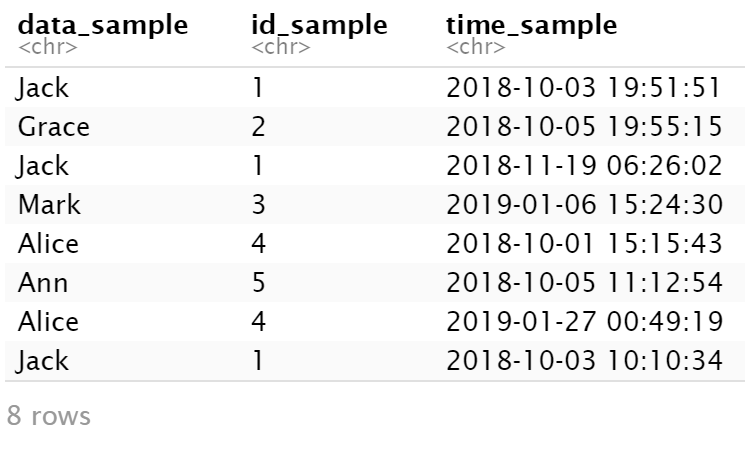
The simple sample dataset is as follows.
data_sample <- c('Jack', 'Grace', 'Jack','Mark', 'Alice', 'Ann', 'Alice', 'Jack')
id_sample <- c(1, 2, 1, 3, 4, 5, 4, 1)
time_sample <- c("2018-10-03 19:51:51",
"2018-10-05 19:55:15",
"2018-11-19 06:26:02",
"2019-01-06 15:24:30",
"2018-10-01 15:15:43",
"2018-10-05 11:12:54",
"2019-01-27 00:49:19",
"2018-10-03 10:10:34")
dat_sample <- as.data.frame(cbind(data_sample, id_sample, time_sample))
dat_sample
dat_cluster <- dat_sample %>% arrange(match(data_sample, unique(data_sample)), time_sample)
dat_cluster
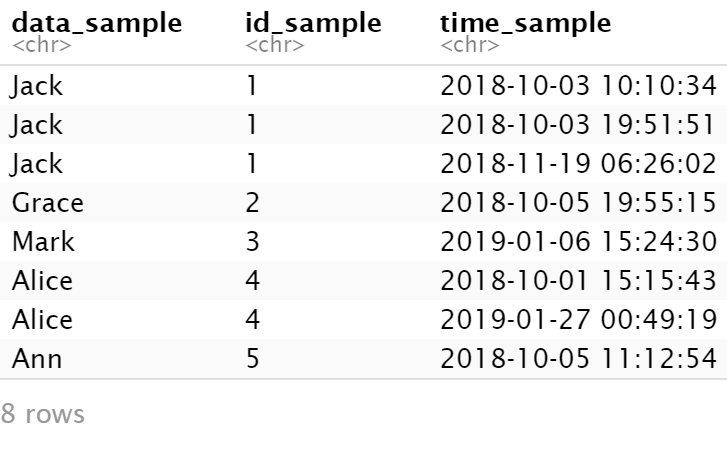
It means Jack has ordered the item for three times and he repurchased; Alice has ordered it twice; Ann, Mark and Grace only ordered it once and they didn't repurchase. Therefore, how can I mutate a new variable, say, whether_to_purcahse for these customers? 1 means repurchase and 0 means no repurchase.
Since I want to transfer the dat_sample into the data frame in excel, shown below,how can I manipulate it in r with tidyverse? I know I need to first ensure whether this person repurchased or not and then I need to know how many times the person has ordered totally if he made any repurchase. Finally, I need to make the long dateset into a wider dataset. However, I have some problem in implementing these steps above. Any suggestions or help?

Thanks so much.