Working through the "Communication" section of the R4DS second edition, and in the subsection on scales. I'm working through one of the exercises that asks me to use the "presidential" dataset that comes with ggplot2 and better communicate the display of presidential terms. Specifically, in this case, I need to improve the display of the Y axis so that the name of the president shows up on the y-axis next to their corresponding point and segment.
(The picture I've uploaded is from this chapter of the book and is the base off of which the exercise question asks me to build. As you see in the picture, the y-axis is "id", which is just the row number of the observation + 33 -- I.E. Obama is row number 11 + 33 = 44th president . But the axis only displays major breaks and labels at 36, 39, 42, 45. I need breaks (presidential$id) and labels (presidential$name) for every president displayed in the plot
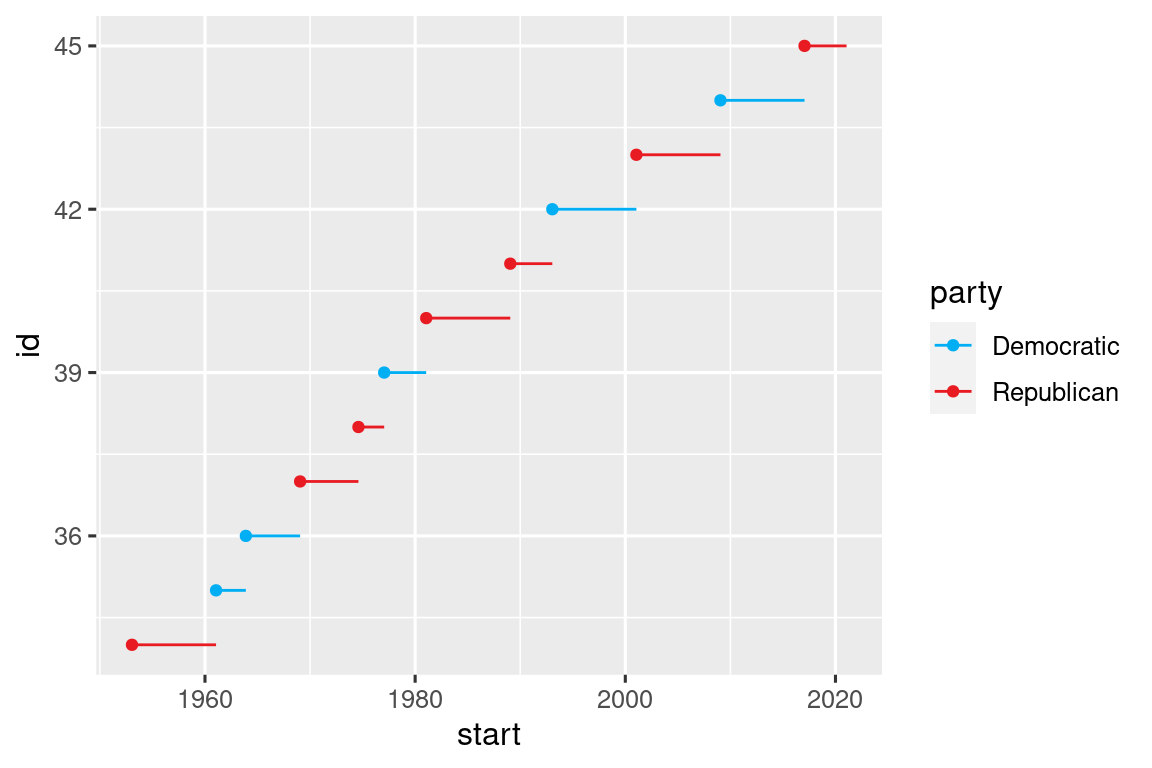
Here is my code below. For whatever reason I get a warning "Warning message:
Unknown or uninitialised column: id." whenever I execute this code and a plot that returns no y-axis breaks or labels.
presidential |>
mutate(id = 33 + row_number()) |>
ggplot(aes(start, id, color = party)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_colour_manual(values = c(Republican = "red", Democratic = "blue")) +
scale_x_date(breaks = presidential$start,
date_labels = "'%y") +
scale_y_continuous(breaks = presidential$id,
labels = presidential$name,
minor_breaks = NULL)
However, when I just make the breaks argument in scale_y_continuous a numerical range (breaks = 33:45), the plot runs as it should?
presidential |>
mutate(id = 33 + row_number()) |>
ggplot(aes(start, id, color = party)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_colour_manual(values = c(Republican = "red", Democratic = "blue")) +
scale_x_date(breaks = presidential$start,
date_labels = "'%y") +
scale_y_continuous(breaks = 34:45,
labels = presidential$name,
minor_breaks = NULL)
Is there a reason that R won't accept presidential$id but will accept the exact same values when written as a sequence of numbers? Thanks for any help or explanation you can provide