Hello!
I have two datasets, one called "PivotMECdata" and one called "FROSTMECDATA". The latter dataset is the PIVOTMECdata merged with another data file. However, when I did this merge, it seems that some observations were taken out.
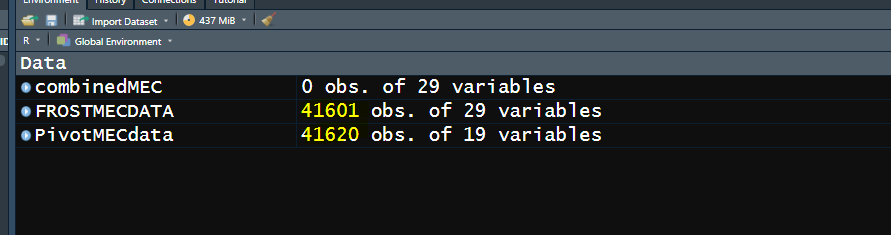
My idea to solve this would be to 're-merge' the two datafiles, but as a left join, so that all of the "PivotMECdata" observations would be there, plus the FROSTMECDATA observations. I figured I could do a 'left join' of sorts, where I joined the shorter dataset onto the longer one, but just had NA values where there was missing data. That way, I could figure out the data points of issue. However, when I used the code below, I got ALL NA values for my appended columns.
combinedMEC <- merge(x=PivotMECdata,y=FROSTMECDATA,all.x = TRUE)
Below, I've provided abbreviated versions of each of the dataframes. One of them is intentionally shorter than the other. I'd like to do a merge so that it would be the same number of rows as the longer one, but with the columns of the shorter one added with "NA" values where there is no data. Hope that makes sense!
#Dataset with no missing values
structure(list(AgeGroup = c("18 - 25", "18 - 25", "18 - 25",
"18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25",
"18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25",
"18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25",
"18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25",
"18 - 25", "18 - 25", "18 - 25"), AgeGroupCensus = c("15 - 24",
"15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24",
"15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24",
"15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24",
"15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24",
"15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24"), Case_Number = c("00006",
"00006", "00036", "00036", "00042", "00042", "0008", "0008",
"00114", "00114", "00114", "00124", "00124", "00139", "00139",
"00139", "00139", "00148", "00148", "00148", "00148", "00157",
"00168", "00168", "00168", "00192", "00193", "00193", "00193",
"00193"), County = c(10, 10, 36, 36, 36, 36, 3, 3, 36, 36, 36,
36, 36, 36, 36, 36, 36, 16, 16, 16, 16, 16, 36, 36, 36, 16, 36,
36, 36, 36), District = c(4, 4, 21, 21, 21, 21, 14, 14, 21, 21,
21, 21, 21, 21, 21, 21, 21, 4, 4, 4, 4, 4, 21, 21, 21, 4, 21,
21, 21, 21), ID = c(57474, 57474, 68515, 68515, 68516, 68516,
64713, 64713, 68540, 68540, 68540, 68546, 68546, 68551, 68551,
68551, 68551, 57540, 57540, 57540, 57540, 57514, 68563, 68563,
68563, 57705, 68577, 68577, 68577, 68577), Manner_of_Death = c("A",
"A", "A", "A", "H", "H", "A", "A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "A", "A", "A", "A", "S", "A", "A", "A", "A", "A",
"A", "A", "A"), MOD = c("Accident", "Accident", "Accident", "Accident",
"Homicide", "Homicide", "Accident", "Accident", "Accident", "Accident",
"Accident", "Accident", "Accident", "Accident", "Accident", "Accident",
"Accident", "Accident", "Accident", "Accident", "Accident", "Suicide",
"Accident", "Accident", "Accident", "Accident", "Accident", "Accident",
"Accident", "Accident"), Month = c(1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 2, 2, 2, 1, 2, 2, 2, 2
), Race = c("W", "W", "W", "W", "B", "B", "W", "W", "W", "W",
"W", "W", "W", "W", "W", "W", "W", "W", "W", "W", "W", "B", "W",
"W", "W", "B", "W", "W", "W", "W"), RaceGroup = c("W", "W", "W",
"W", "B", "B", "W", "W", "W", "W", "W", "W", "W", "W", "W", "W",
"W", "W", "W", "W", "W", "B", "W", "W", "W", "B", "W", "W", "W",
"W"), RecID = c("2021252", "2021252", "202110337", "202110337",
"202110338", "202110338", "20217432", "20217432", "202110362",
"202110362", "202110362", "202110368", "202110368", "202110373",
"202110373", "202110373", "202110373", "2021318", "2021318",
"2021318", "2021318", "2021292", "202110385", "202110385", "202110385",
"2021483", "202110399", "202110399", "202110399", "202110399"
), Gender = c("M", "M", "M", "M", "M", "M", "M", "M", "M", "M",
"M", "F", "F", "F", "F", "F", "F", "M", "M", "M", "M", "M", "M",
"M", "M", "F", "F", "F", "F", "F"), Year = c(2021, 2021, 2021,
2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021,
2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021,
2021, 2021, 2021, 2021, 2021), Age = c(24, 24, 23, 23, 21, 21,
22, 22, 22, 22, 22, 23, 23, 21, 21, 21, 21, 24, 24, 24, 24, 23,
20, 20, 20, 23, 20, 20, 20, 20), Poly = c(1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1,
1, 1), Type = c("P", "P", "P", "P", "P", "P", "P", "P", "P",
"C", "P", "C", "C", "P", "C", "P", "P", "P", "C", "C", "P", "P",
"P", "C", "P", "P", "C", "C", "P", "P"), drug = c("Cannabinoids",
"Ethanol", "Cannabinoids", "Ethanol", "Cannabinoids", "Ethanol",
"Cannabinoids", "Ethanol", "Cannabinoids", "Fentanyl", "FentanylAnalogs",
"Amphetamine", "Methamphetamine", "Ethanol", "Fentanyl", "FentanylAnalogs",
"Mitragynine", "Cannabinoids", "Cocaine", "Ethanol", "Fentanyl",
"Ethanol", "Cocaine", "Fentanyl", "FentanylAnalogs", "Cannabinoids",
"Cocaine", "Fentanyl", "FentanylAnalogs", "HallucinogenicPhenethylaminesPip"
), Data_Source = c("2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021")), row.names = c(NA,
-30L), class = c("tbl_df", "tbl", "data.frame"))
>
#DATASET WITH MISSING VALUES
structure(list(County = c("Clay", "Clay", "Lee", "Lee", "Lee",
"Lee", "Bay", "Bay", "Lee", "Lee", "Lee", "Lee", "Lee", "Lee",
"Lee", "Lee", "Lee", "Duval", "Duval", "Duval"), FIPS = c(12019,
12019, 12071, 12071, 12071, 12071, 12005, 12005, 12071, 12071,
12071, 12071, 12071, 12071, 12071, 12071, 12071, 12031, 12031,
12031), CrosswalkYear = c(2016, 2016, 2016, 2016, 2016, 2016,
2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016,
2016, 2016, 2016), CountyNum = c(10, 10, 36, 36, 36, 36, 3, 3,
36, 36, 36, 36, 36, 36, 36, 36, 36, 16, 16, 16), District = c("JACKSONVILLE",
"JACKSONVILLE", "FT. MYERS", "FT. MYERS", "FT. MYERS", "FT. MYERS",
"PANAMA CITY", "PANAMA CITY", "FT. MYERS", "FT. MYERS", "FT. MYERS",
"FT. MYERS", "FT. MYERS", "FT. MYERS", "FT. MYERS", "FT. MYERS",
"FT. MYERS", "JACKSONVILLE", "JACKSONVILLE", "JACKSONVILLE"),
DistrictNum = c(4, 4, 21, 21, 21, 21, 14, 14, 21, 21, 21,
21, 21, 21, 21, 21, 21, 4, 4, 4), CoveredBy = c(4, 4, 21,
21, 21, 21, 14, 14, 21, 21, 21, 21, 21, 21, 21, 21, 21, 4,
4, 4), CountyUPPER = c("CLAY", "CLAY", "LEE", "LEE", "LEE",
"LEE", "BAY", "BAY", "LEE", "LEE", "LEE", "LEE", "LEE", "LEE",
"LEE", "LEE", "LEE", "DUVAL", "DUVAL", "DUVAL"), HIDTA2020 = c("North Florida",
"North Florida", "Non-HIDTA", "Non-HIDTA", "Non-HIDTA", "Non-HIDTA",
"Non-HIDTA", "Non-HIDTA", "Non-HIDTA", "Non-HIDTA", "Non-HIDTA",
"Non-HIDTA", "Non-HIDTA", "Non-HIDTA", "Non-HIDTA", "Non-HIDTA",
"Non-HIDTA", "North Florida", "North Florida", "North Florida"
), Year_2020 = c(2020, 2020, 2020, 2020, 2020, 2020, 2020,
2020, 2020, 2020, 2020, 2020, 2020, 2020, 2020, 2020, 2020,
2020, 2020, 2020), CTYNAME = c("Clay County", "Clay County",
"Lee County", "Lee County", "Lee County", "Lee County", "Bay County",
"Bay County", "Lee County", "Lee County", "Lee County", "Lee County",
"Lee County", "Lee County", "Lee County", "Lee County", "Lee County",
"Duval County", "Duval County", "Duval County"), Population = c(218797,
218797, 764679, 764679, 764679, 764679, 174461, 174461, 764679,
764679, 764679, 764679, 764679, 764679, 764679, 764679, 764679,
996373, 996373, 996373), AgeGroup = c("18 - 25", "18 - 25",
"18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25",
"18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25",
"18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25", "18 - 25"
), AgeGroupCensus = c("15 - 24", "15 - 24", "15 - 24", "15 - 24",
"15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24",
"15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24", "15 - 24",
"15 - 24", "15 - 24", "15 - 24", "15 - 24"), Case_Number = c("00006",
"00006", "00036", "00036", "00042", "00042", "0008", "0008",
"00114", "00114", "00114", "00124", "00124", "00139", "00139",
"00139", "00139", "00148", "00148", "00148"), ID = c(57474,
57474, 68515, 68515, 68516, 68516, 64713, 64713, 68540, 68540,
68540, 68546, 68546, 68551, 68551, 68551, 68551, 57540, 57540,
57540), Manner_of_Death = c("A", "A", "A", "A", "H", "H",
"A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A",
"A", "A"), MOD = c("Accident", "Accident", "Accident", "Accident",
"Homicide", "Homicide", "Accident", "Accident", "Accident",
"Accident", "Accident", "Accident", "Accident", "Accident",
"Accident", "Accident", "Accident", "Accident", "Accident",
"Accident"), Month = c(1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 2, 2, 2, 1, 1, 1), Race = c("W", "W", "W", "W", "B",
"B", "W", "W", "W", "W", "W", "W", "W", "W", "W", "W", "W",
"W", "W", "W"), RaceGroup = c("W", "W", "W", "W", "B", "B",
"W", "W", "W", "W", "W", "W", "W", "W", "W", "W", "W", "W",
"W", "W"), RecID = c("2021252", "2021252", "202110337", "202110337",
"202110338", "202110338", "20217432", "20217432", "202110362",
"202110362", "202110362", "202110368", "202110368", "202110373",
"202110373", "202110373", "202110373", "2021318", "2021318",
"2021318"), Gender = c("M", "M", "M", "M", "M", "M", "M",
"M", "M", "M", "M", "F", "F", "F", "F", "F", "F", "M", "M",
"M"), Year = c(2021, 2021, 2021, 2021, 2021, 2021, 2021,
2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021,
2021, 2021, 2021), Age = c(24, 24, 23, 23, 21, 21, 22, 22,
22, 22, 22, 23, 23, 21, 21, 21, 21, 24, 24, 24), Poly = c(1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1),
drug = c("Cannabinoids", "Ethanol", "Cannabinoids", "Ethanol",
"Cannabinoids", "Ethanol", "Cannabinoids", "Ethanol", "Cannabinoids",
"Fentanyl", "FentanylAnalogs", "Amphetamine", "Methamphetamine",
"Ethanol", "Fentanyl", "FentanylAnalogs", "Mitragynine",
"Cannabinoids", "Cocaine", "Ethanol"), Type = c("P", "P",
"P", "P", "P", "P", "P", "P", "P", "C", "P", "C", "C", "P",
"C", "P", "P", "P", "C", "C"), Data_Source = c("2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021", "2021 Annual Raw Data UF.xlsx/RawDataClean2021",
"2021 Annual Raw Data UF.xlsx/RawDataClean2021")), row.names = c(NA,
-20L), class = c("tbl_df", "tbl", "data.frame"))