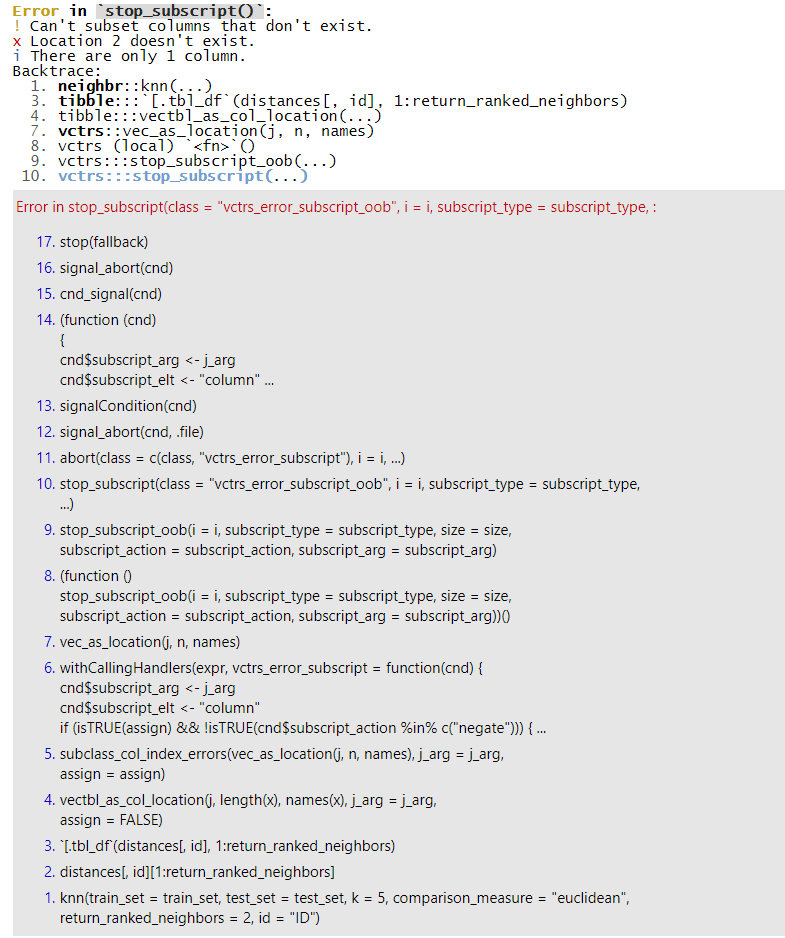
Below is now the reprex. I hope this is right as the ID column has the values below with an L (I created the column using the rowid_to_column() function. However, with just the small sample the function works without an error. I still get the error when I use the full dataset. why?
df_train<-data.frame(stringsAsFactors = FALSE,
check.names = FALSE,
ID = c(1L,2L,
3L,4L,5L,6L,7L,8L,9L,10L,11L,12L,
13L,14L,15L,16L,17L,18L,19L,20L),
BD_research = c(0,1,0,
1,0,0,0,1,1,0,0,0,0,0,0,0,0,0,
0,0),
BD_RD = c(0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0),
BD_develop = c(0,1,0,
1,0,0,1,1,1,1,1,0,1,1,1,0,0,1,
1,0),
BD_discover = c(0,0,0,
0,0,0,0,0,0,0,1,0,0,0,0,0,0,1,
0,0),
`Private Company` = c(1,1,0,
0,1,1,1,0,0,1,0,0,0,0,0,1,1,1,
1,1),
`Public Company` = c(0,0,1,
1,0,0,0,1,1,0,1,1,1,1,1,0,0,0,
0,0),
Number_Employees = c(-0.11129043029361,-0.133882618992182,
-0.152212130577816,-0.0599251710827047,
-0.0957316588313852,-0.0386117855180139,-0.0955185249757383,
-0.142194839362411,-0.123225926209836,
-0.143899910207586,-0.130472477301831,
-0.0490553444447124,-0.148162587320525,
-0.14432617791888,-0.148588855031818,-0.142407973218058,
-0.110437894871022,-0.148375721176171,
-0.0571544309592949,-0.0733526039884599),
Total_Revenue = c(-0.0980542624611477,-0.100277064165423,
-0.111073529586189,-0.0958314607568724,
-0.0770964178208376,0.019754227865444,-0.0993244348635908,
-0.112026158888021,-0.11170861578741,
-0.110438443384967,-0.112026158888021,
-0.0755087023177838,-0.112026158888021,
-0.112026158888021,-0.112026158888021,-0.109803357183746,
-0.0888455125434357,-0.111073529586189,
-0.0929735728513756,-0.0466122801622047)
)
df_test<-data.frame(stringsAsFactors = FALSE,
check.names = FALSE,
BD_research = c(0, 1, 0, 0, 0, 0),
BD_RD = c(0, 0, 0, 0, 0, 0),
BD_develop = c(0, 1, 1, 0, 0, 0),
BD_discover = c(0, 0, 0, 0, 0, 0),
`Private Company` = c(1, 1, 0, 1, 1, 1),
`Public Company` = c(0, 0, 1, 0, 0, 0),
Number_Employees = c(-0.131751280435713,-0.13814529610512,
0.417068397855075,-0.136013957548651,-0.153064666000403,
-0.152851532144757),
Total_Revenue = c(-0.104087581372752,-0.108533184781303,
0.479874180650434,-0.105040210674584,
-0.0932911159519863,-0.112026158888021)
)
library(neighbr)
#> Warning: package 'neighbr' was built under R version 4.1.3
f<-knn(train_set=df_train, test_set = df_test,
k=3,
comparison_measure = "euclidean",
return_ranked_neighbors = 2,
id="ID")
Created on 2022-12-17 with reprex v2.0.2
Thanks again for your help!