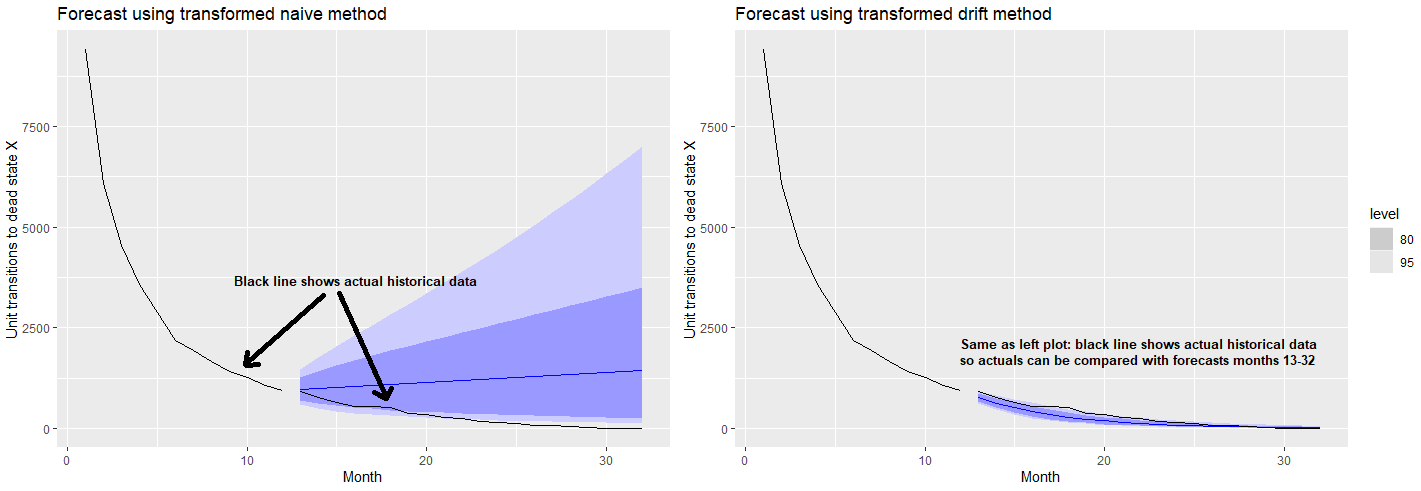
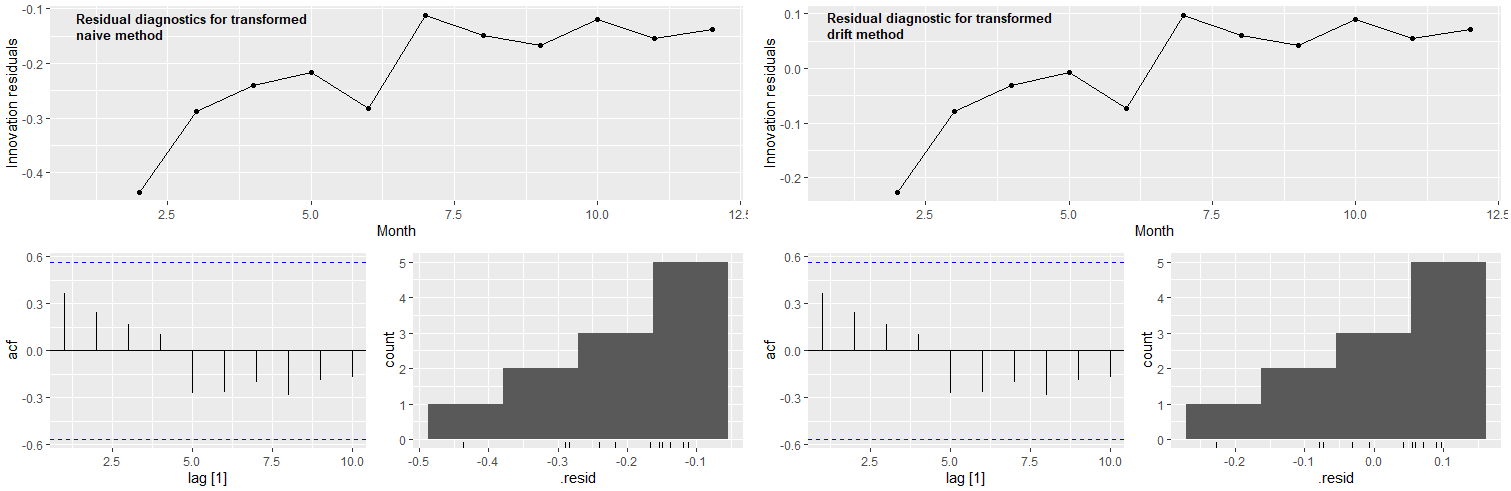
I am working through Hyndman, R.J., & Athanasopoulos, G. (2021) Forecasting: principles and practice , 3rd edition, OTexts: Melbourne, Australia. Forecasting: Principles and Practice (3rd ed) (accessed on 30 January 2023). I am interested in generating point and interval forecasts for autocorrelated, non-seasonal time series data that shows exponential decay when expressed as unit transitions to "State X", and otherwise a logarithmic function when those unit transitions are instead expressed as a percentage of initial population units (basically reversing the exponential decay curve). As a frequent user of Stack Overflow I posted a related question on r - Which models to use when forecasting time series data that shows exponential decay? - Cross Validated.
I've been going through the list of models available in the fable package (Forecasting Models for Tidy Time Series • fable) and am having trouble figuring out if there is a better type of model suited for my exponential decay situation (or its logarithmic corollary when expressed as a percentage of initial units in the population). Is there a type of model better suited for this type of data? I've been working through ARIMA, RW, and ETS models so far.
Referred here by Forecasting: Principles and Practice, by Rob J Hyndman and George Athanasopoulos